Semantic RGB-D Perception for Cognitive Robots
|
|
|
- Sharyl Boone
- 6 years ago
- Views:
Transcription

1 Semantic RGB-D Perception for Cognitive Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems


2 Our Domestic Service Robots Dynamaid Cosero Size: cm, weight: kg 36 articulated joints PC, laser scanners, Kinect, microphone, 2

3 RoboCup 2013 Eindhoven 3

 Flexible grasping of many")

4 Analysis of Table-top Scenes and Grasp Planning Detection of clusters above horizontal plane Two grasps (top, side) Flexible grasping of many unknown objects [Stückler, Steffens, Holz, Behnke, Robotics and Autonomous Systems 2012] 4

5 3D-Mapping with Surfels 5

6 3D-Mapping with Surfels 6

7 3D-Mapping and Localization Registration of 3D laser scans Representation of point distributions in voxels Drivability assessment trough region growing Robust localization using 2D laser scans [Kläß, Stückler, Behnke: Robotik 2012] 7








8 3D Mapping by RGB-D SLAM Modelling of shape and color distributions in voxels Local multiresolution Efficient registration of views on CPU Global optimization [Stückler, Behnke: Journal of Visual Communication and Image Representation 2013] 2,5cm 5cm Multi-camera SLAM [Stoucken, Diplomarbeit 2013] 8





9 Learning and Tracking Object Models Modeling of objects by RGB-D-SLAM Real-time registration with current RGB-D image 9


![& Song, PAMI 2010]](/docs-images/74/70241388/images/10-2.jpg "Multiresolution Surfel")

10 Deformable RGB-D-Registration Based on Coherent Point Drift method [Myronenko & Song, PAMI 2010] Multiresolution Surfel Map allows real-time registration [Stückler, Behnke, ICRA2014] 10

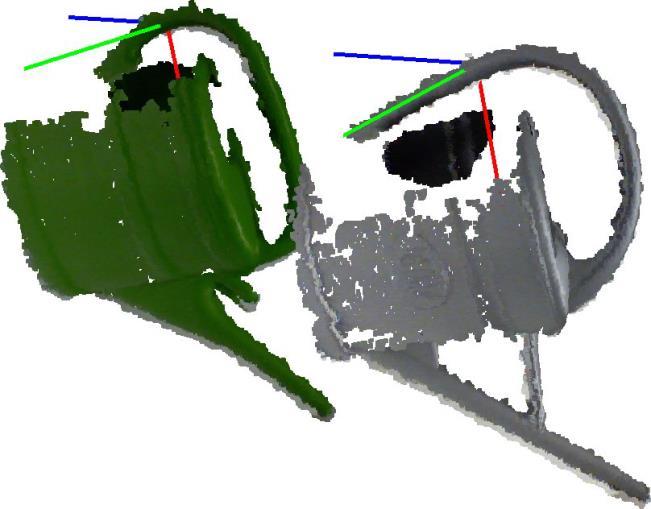


11 Transformation of Poses on Object Derived from the deformation field [Stückler, Behnke, ICRA2014] 11
12 Grasp & Motion Skill Transfer Demonstration at RoboCup 2013 [Stückler, Behnke, ICRA2014] 12




13 Tool use: Bottle Opener Tool tip perception Extension of arm kinematics Perception of crown cap Motion adaptation [Stückler, Behnke, Humanoids 2014] 13


14 Picking Sausage, Bimanual Transport Perception of tool tip and sausage Alignment with main axis of sausage Our team NimbRo won the League in three consecutive years [Stückler, Behnke, Humanoids 2014] 14



15 Hierarchical Object Discovery trough Motion Segmentation Motion is strong segmentation cue Both camera and object motion Segment-wise registration of a sequence Inference of a segment hierarchy [Stückler, Behnke: IJCAI 2013] 15





16 Semantic Mapping Pixel-wise classification of RGB-D images by random forests Inner nodes compare color / depth of regions Size normalization Training and recall on GPU 3D fusion through RGB-D SLAM Evaluation on own data set and NYU depth v2 [Stückler, Biresev, Behnke: IROS 2012] Accuracy in % Ø Classes Ø Pixels Ground truth Segmentation Silberman et al ,6 58,6 Couprie et al ,5 64,5 Random forest 65,0 68,1 3D-Fusion 66,8 70,6 [Stückler et al., Journal of Real-Time Image Processing 2014] 16




17 Learning Depth-sensitive CRFs SLIC+depth super pixels Unary features: random forest Height feature Pairwise features Color contrast Vertical alignment Depth difference Normal differences Results: similarity between superpixel normals Random forest CRF prediction Ground truth [Müller and Behnke, ICRA 2014] 17




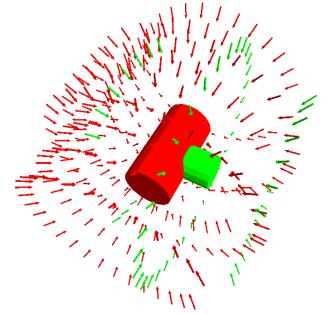
18 Object Class Detection in RGB-D Hough forests make not only object class decision, but describe object center RGB-D objects data set Color and depth features Training with rendered scenes Detection of object position and orientation Scene Class prob. Object centers Orientation Detected objects Depth helps a lot [Badami, Stückler, Behnke: SPME 2013] 18













19 Bin Picking Known objects in transport box Matching of graphs of 2D and 3D shape primitives 3D 2D Grasp and motion planning Offline Online [Nieuwenhuisen et al.: ICRA 2013] 19


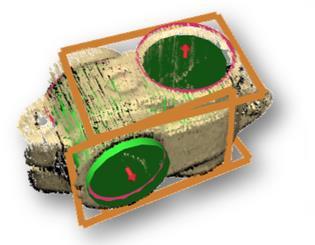
20 Learning of Object Models Scan multiple objects in different poses Find support plane and remove it Segment views Register views using ICP Recognize geometric primitives Registered views Surface reconstruction Detected primitives 20

![2014]](/docs-images/74/70241388/images/21-1.jpg "Active")
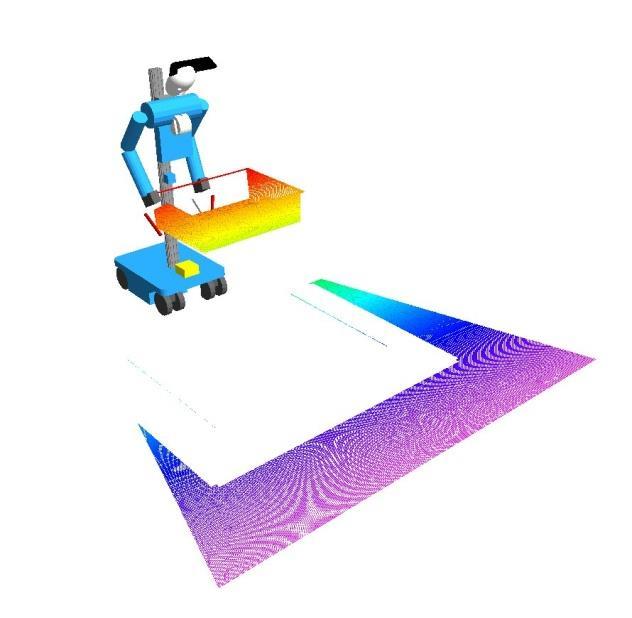
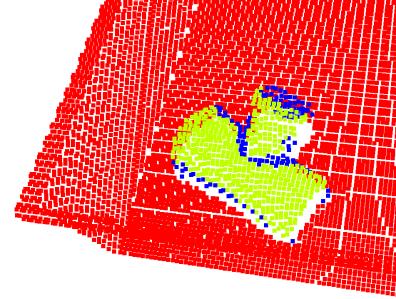
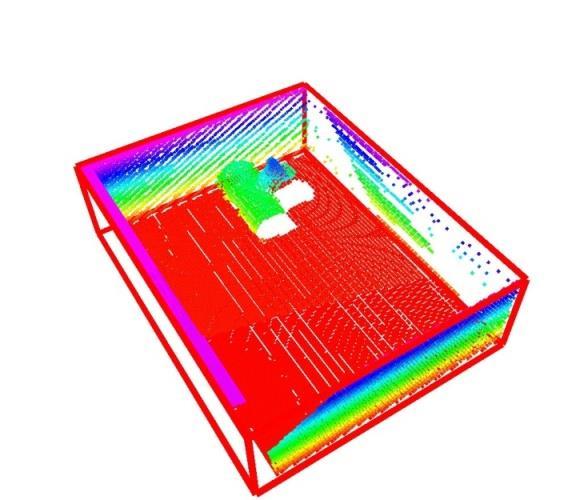
21 [Holz et al. STAR 2014] Active Object Perception

22 Active Object Perception Detected cylinders Partial occlusions Detected object Efficient exploration of the part arrangement in the transport boxes to handle occlusions [Holz et al. STAR 2014]


23 Active Object Perception Next best view Efficient exploration of the part arrangement in the transport boxes to handle occlusions

24 Active Object Perception Two more detected objects Efficient exploration of the part arrangement in the transport boxes to handle occlusions [Holz et al. STAR 2014]

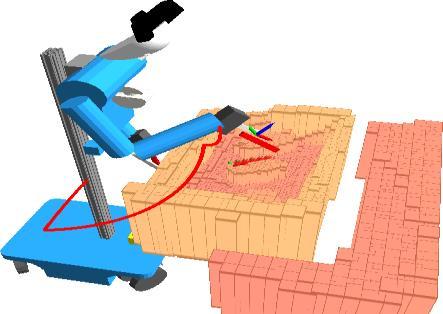
25 Industrial Application: Depalettizing Using work space RGB-D camera Initial pose of transport box roughly known Detect dominant horizontal plane above ground Cluster points above support plane Estimate main axes [Holz et al. IROS 2015] 25

26 Object View Registration Wrist RGB-D camera moved above innermost object candidate Object views are represented as Multiresolution Surfel Map Registration of object view with current measurements using soft assignments Verification based on registration quality [Holz et al. IROS 2015] 26

27 Part Detection and Grasping [Holz et al. IROS 2015] 27


28 Depalletizing Results: 10 Runs Total time Component times and success rates [Holz et al. IROS 2015] 28


29 Part Verification Results Parts used for verification Detection confidences [Holz et al. IROS 2015] 29



30 Different Lighting Conditions Artificial light and day light Only daylight Low light In all cases, the palette was successfully cleared. [Holz et al. IROS 2015] 30

31 Deep Learning [Schulz and Behnke, KI 2012] 31


![[Scherer & Behnke, 2009]](/docs-images/74/70241388/images/32-2.jpg "Local connectivity [Uetz &")
32 GPU Implementations (CUDA) Affordable parallel computers General-purpose programming Convolutional [Scherer & Behnke, 2009] Local connectivity [Uetz & Behnke, 2009] 32


33 Image Categorization: NORB 10 categories, jittered-cluttered Max-Pooling, cross-entropy training Test error: 5,6% (LeNet7: 7.8%) [Scherer, Müller, Behnke, ICANN 10] 33
 Error TRN: 3.77%; TST: 16.")
34 Image Categorization: LabelMe 50,000 color images (256x256) 12 classes + clutter (50%) Error TRN: 3.77%; TST: 16.27% Recall: 1,356 images/s [Uetz, Behnke, ICIS2009] 34




35 Object-class Segmentation Class annotation per pixel [Schulz, Behnke 2012] Multi-scale input channels Evaluated on MSRC-9/21 and INRIA Graz-02 data sets Input Output Truth Input Output Truth 35

36 Object Detection in Images Bounding box annotation Structured loss that directly maximizes overlap of the prediction with ground truth bounding boxes Evaluated on two of the Pascal VOC 2007 classes [Schulz, Behnke, ICANN 2014] 36


37 RGB-D Object-Class Segmentation Scale input according to depth Compute pixel height NYU Depth V2 RGB Depth Height Truth Output [Schulz, Höft, Behnke, ESANN 2015] 37
38 Neural Abstraction Pyramid [Behnke, LNCS 2766, 2003] Abstract features - Data-driven - Analysis - Feature extraction - Model-driven - Synthesis - Feature expansion - Grouping - Competition - Completion Signals 38

![2766, 2003] Use partial interpretation](/docs-images/74/70241388/images/39-1.jpg "as context to resolve local")
39 Iterative Interpretation Interpret most obvious parts first [Behnke, LNCS 2766, 2003] Use partial interpretation as context to resolve local ambiguities 39

40 Local Recurrent Connectivity Lateral projection Backward projection Hyper column Forward projection Feature map Cell Layer Processor element Layer Projections Output Layer Hyper neighborhood Less abstract [Behnke, LNCS 2766, 2003] More abstract 40



41 Neural Abstraction Pyramid for RGB-D Video Object-class Segmentation NYU Depth V2 contains RGB-D video sequences Recursive computation is efficient for temporal integration RGB Depth Output Truth [Pavel, Schulz, Behnke, IJCNN 2015] 41

42 Geometric and Semantic Features for RGB-D Object-class Segmentation New geometric feature: distance from wall Semantic features pretrained from ImageNet Both help significantly [Husain et al. under review] RGB Truth DistWall OutWO OutWithDist 42


43 Semantic Segmentation Priors for Object Discovery Combine bottomup object discovery and semantic priors Semantic segmentation used to classify color and depth superpixels Higher recall, more precise object borders [Garcia et al. under review] 43

44 RGB-D Object Recognition and Pose Estimation Use pretrained features from ImageNet [Schwarz, Schulz, Behnke, ICRA2015] 44



45 Canonical View, Colorization Objects viewed from different elevation Render canonical view Colorization based on distance from center vertical [Schwarz, Schulz, Behnke, ICRA2015] 45

46 Features Disentangle Data t-sne embedding [Schwarz, Schulz, Behnke ICRA2015] 46


47 Recognition Accuracy Improved both category and instance recognition Confusion 1: pitcher / coffe mug 2: peach / sponge [Schwarz, Schulz, Behnke, ICRA2015] 47
48 Conclusion Semantic perception in everyday environments is challenging Simple methods rely on strong assumptions (e.g. support plane) Depth helps with segmentation, allows for size normalization, geometric features, shape descriptors Deep learning methods work well Transfer of features from large data sets Many open problems, e.g. total scene understanding, incorporating physics, 48
49 Thanks for your attention! Questions? 49
Learning Semantic Environment Perception for Cognitive Robots
 Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Learning Semantic Environment Perception for Cognitive Robots Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems Some of Our Cognitive Robots Equipped
Visual Perception for Robots
 Visual Perception for Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Cognitive Robots Complete systems for example scenarios Equipped with rich sensors Flying robot
Visual Perception for Robots Sven Behnke Computer Science Institute VI Autonomous Intelligent Systems Our Cognitive Robots Complete systems for example scenarios Equipped with rich sensors Flying robot
Manipulating a Large Variety of Objects and Tool Use in Domestic Service, Industrial Automation, Search and Rescue, and Space Exploration
 Manipulating a Large Variety of Objects and Tool Use in Domestic Service, Industrial Automation, Search and Rescue, and Space Exploration Sven Behnke Computer Science Institute VI Autonomous Intelligent
Manipulating a Large Variety of Objects and Tool Use in Domestic Service, Industrial Automation, Search and Rescue, and Space Exploration Sven Behnke Computer Science Institute VI Autonomous Intelligent
Deep Learning for Visual Perception
 SA-1 Deep Learning for Visual Perception Sven Behnke University of Bonn Computer Science Institute VI Autonomous Intelligent Systems Much Interest in Deep Learning [Google Trends] 2 Industry Acquisitions
SA-1 Deep Learning for Visual Perception Sven Behnke University of Bonn Computer Science Institute VI Autonomous Intelligent Systems Much Interest in Deep Learning [Google Trends] 2 Industry Acquisitions
Active Recognition and Manipulation of Simple Parts Exploiting 3D Information
 experiment ActReMa Active Recognition and Manipulation of Simple Parts Exploiting 3D Information Experiment Partners: Rheinische Friedrich-Wilhelms-Universität Bonn Metronom Automation GmbH Experiment
experiment ActReMa Active Recognition and Manipulation of Simple Parts Exploiting 3D Information Experiment Partners: Rheinische Friedrich-Wilhelms-Universität Bonn Metronom Automation GmbH Experiment
Learning Depth-Sensitive Conditional Random Fields for Semantic Segmentation of RGB-D Images
 Learning Depth-Sensitive Conditional Random Fields for Semantic Segmentation of RGB-D Images Andreas C. Müller and Sven Behnke Abstract We present a structured learning approach to semantic annotation
Learning Depth-Sensitive Conditional Random Fields for Semantic Segmentation of RGB-D Images Andreas C. Müller and Sven Behnke Abstract We present a structured learning approach to semantic annotation
3D Simultaneous Localization and Mapping and Navigation Planning for Mobile Robots in Complex Environments
 3D Simultaneous Localization and Mapping and Navigation Planning for Mobile Robots in Complex Environments Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems
3D Simultaneous Localization and Mapping and Navigation Planning for Mobile Robots in Complex Environments Sven Behnke University of Bonn, Germany Computer Science Institute VI Autonomous Intelligent Systems
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction
 Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Discrete Optimization of Ray Potentials for Semantic 3D Reconstruction Marc Pollefeys Joined work with Nikolay Savinov, Christian Haene, Lubor Ladicky 2 Comparison to Volumetric Fusion Higher-order ray
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks
 Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
Fast Semantic Segmentation of RGB-D Scenes with GPU-Accelerated Deep Neural Networks Nico Höft, Hannes Schulz, and Sven Behnke Rheinische Friedrich-Wilhelms-Universität Bonn Institut für Informatik VI,
Perceiving the 3D World from Images and Videos. Yu Xiang Postdoctoral Researcher University of Washington
 Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
Perceiving the 3D World from Images and Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World 3 Understand
3D Object Recognition and Scene Understanding from RGB-D Videos. Yu Xiang Postdoctoral Researcher University of Washington
 3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
3D Object Recognition and Scene Understanding from RGB-D Videos Yu Xiang Postdoctoral Researcher University of Washington 1 2 Act in the 3D World Sensing & Understanding Acting Intelligent System 3D World
CRF Based Point Cloud Segmentation Jonathan Nation
 CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
CRF Based Point Cloud Segmentation Jonathan Nation jsnation@stanford.edu 1. INTRODUCTION The goal of the project is to use the recently proposed fully connected conditional random field (CRF) model to
Deformable Part Models
 CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
CS 1674: Intro to Computer Vision Deformable Part Models Prof. Adriana Kovashka University of Pittsburgh November 9, 2016 Today: Object category detection Window-based approaches: Last time: Viola-Jones
Learning and Inferring Depth from Monocular Images. Jiyan Pan April 1, 2009
 Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Learning and Inferring Depth from Monocular Images Jiyan Pan April 1, 2009 Traditional ways of inferring depth Binocular disparity Structure from motion Defocus Given a single monocular image, how to infer
Object Classification in Domestic Environments
 Object Classification in Domestic Environments Markus Vincze Aitor Aldoma, Markus Bader, Peter Einramhof, David Fischinger, Andreas Huber, Lara Lammer, Thomas Mörwald, Sven Olufs, Ekaterina Potapova, Johann
Object Classification in Domestic Environments Markus Vincze Aitor Aldoma, Markus Bader, Peter Einramhof, David Fischinger, Andreas Huber, Lara Lammer, Thomas Mörwald, Sven Olufs, Ekaterina Potapova, Johann
Human Body Recognition and Tracking: How the Kinect Works. Kinect RGB-D Camera. What the Kinect Does. How Kinect Works: Overview
 Human Body Recognition and Tracking: How the Kinect Works Kinect RGB-D Camera Microsoft Kinect (Nov. 2010) Color video camera + laser-projected IR dot pattern + IR camera $120 (April 2012) Kinect 1.5 due
Human Body Recognition and Tracking: How the Kinect Works Kinect RGB-D Camera Microsoft Kinect (Nov. 2010) Color video camera + laser-projected IR dot pattern + IR camera $120 (April 2012) Kinect 1.5 due
Lecture 19: Depth Cameras. Visual Computing Systems CMU , Fall 2013
 Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
Lecture 19: Depth Cameras Visual Computing Systems Continuing theme: computational photography Cameras capture light, then extensive processing produces the desired image Today: - Capturing scene depth
Multi-View 3D Object Detection Network for Autonomous Driving
 Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Multi-View 3D Object Detection Network for Autonomous Driving Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, Tian Xia CVPR 2017 (Spotlight) Presented By: Jason Ku Overview Motivation Dataset Network Architecture
Structured Light II. Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov
 Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
Structured Light II Johannes Köhler Johannes.koehler@dfki.de Thanks to Ronen Gvili, Szymon Rusinkiewicz and Maks Ovsjanikov Introduction Previous lecture: Structured Light I Active Scanning Camera/emitter
UNDERSTANDING complex scenes has gained much
 IEEE ROBOTICS AND AUTOMATION LETTERS. PREPRINT VERSION. ACCEPTED JANUARY, 06 Combining Semantic and Geometric Features for Object Class Segmentation of Indoor Scenes Farzad Husain, Hannes Schulz, Babette
IEEE ROBOTICS AND AUTOMATION LETTERS. PREPRINT VERSION. ACCEPTED JANUARY, 06 Combining Semantic and Geometric Features for Object Class Segmentation of Indoor Scenes Farzad Husain, Hannes Schulz, Babette
CS395T paper review. Indoor Segmentation and Support Inference from RGBD Images. Chao Jia Sep
 CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
CS395T paper review Indoor Segmentation and Support Inference from RGBD Images Chao Jia Sep 28 2012 Introduction What do we want -- Indoor scene parsing Segmentation and labeling Support relationships
Accurate 3D Face and Body Modeling from a Single Fixed Kinect
 Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
Accurate 3D Face and Body Modeling from a Single Fixed Kinect Ruizhe Wang*, Matthias Hernandez*, Jongmoo Choi, Gérard Medioni Computer Vision Lab, IRIS University of Southern California Abstract In this
3D object recognition used by team robotto
 3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
3D object recognition used by team robotto Workshop Juliane Hoebel February 1, 2016 Faculty of Computer Science, Otto-von-Guericke University Magdeburg Content 1. Introduction 2. Depth sensor 3. 3D object
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK
 TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
TRANSPARENT OBJECT DETECTION USING REGIONS WITH CONVOLUTIONAL NEURAL NETWORK 1 Po-Jen Lai ( 賴柏任 ), 2 Chiou-Shann Fuh ( 傅楸善 ) 1 Dept. of Electrical Engineering, National Taiwan University, Taiwan 2 Dept.
Scanning and Printing Objects in 3D
 Scanning and Printing Objects in 3D Dr. Jürgen Sturm metaio GmbH (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects
Scanning and Printing Objects in 3D Dr. Jürgen Sturm metaio GmbH (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects
3D Computer Vision. Structured Light II. Prof. Didier Stricker. Kaiserlautern University.
 3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Computer Vision Structured Light II Prof. Didier Stricker Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de 1 Introduction
3D Shape Analysis with Multi-view Convolutional Networks. Evangelos Kalogerakis
 3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
3D Shape Analysis with Multi-view Convolutional Networks Evangelos Kalogerakis 3D model repositories [3D Warehouse - video] 3D geometry acquisition [KinectFusion - video] 3D shapes come in various flavors
Machine Learning for Medical Image Analysis. A. Criminisi
 Machine Learning for Medical Image Analysis A. Criminisi Overview Introduction to machine learning Decision forests Applications in medical image analysis Anatomy localization in CT Scans Spine Detection
Machine Learning for Medical Image Analysis A. Criminisi Overview Introduction to machine learning Decision forests Applications in medical image analysis Anatomy localization in CT Scans Spine Detection
(Deep) Learning for Robot Perception and Navigation. Wolfram Burgard
 Learning for Robot Perception and Navigation. Wolfram Burgard") (Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
(Deep) Learning for Robot Perception and Navigation Wolfram Burgard Deep Learning for Robot Perception (and Navigation) Lifeng Bo, Claas Bollen, Thomas Brox, Andreas Eitel, Dieter Fox, Gabriel L. Oliveira,
Semantic Mapping and Reasoning Approach for Mobile Robotics
 Semantic Mapping and Reasoning Approach for Mobile Robotics Caner GUNEY, Serdar Bora SAYIN, Murat KENDİR, Turkey Key words: Semantic mapping, 3D mapping, probabilistic, robotic surveying, mine surveying
Semantic Mapping and Reasoning Approach for Mobile Robotics Caner GUNEY, Serdar Bora SAYIN, Murat KENDİR, Turkey Key words: Semantic mapping, 3D mapping, probabilistic, robotic surveying, mine surveying
Exploiting Depth Camera for 3D Spatial Relationship Interpretation
 Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
Exploiting Depth Camera for 3D Spatial Relationship Interpretation Jun Ye Kien A. Hua Data Systems Group, University of Central Florida Mar 1, 2013 Jun Ye and Kien A. Hua (UCF) 3D directional spatial relationships
CAP 6412 Advanced Computer Vision
 CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
CAP 6412 Advanced Computer Vision http://www.cs.ucf.edu/~bgong/cap6412.html Boqing Gong April 21st, 2016 Today Administrivia Free parameters in an approach, model, or algorithm? Egocentric videos by Aisha
Efficient Surface and Feature Estimation in RGBD
 Efficient Surface and Feature Estimation in RGBD Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München RGB-D Workshop on 3D Perception
Efficient Surface and Feature Estimation in RGBD Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München RGB-D Workshop on 3D Perception
LSTM and its variants for visual recognition. Xiaodan Liang Sun Yat-sen University
 LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
LSTM and its variants for visual recognition Xiaodan Liang xdliang328@gmail.com Sun Yat-sen University Outline Context Modelling with CNN LSTM and its Variants LSTM Architecture Variants Application in
The Kinect Sensor. Luís Carriço FCUL 2014/15
 Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Advanced Interaction Techniques The Kinect Sensor Luís Carriço FCUL 2014/15 Sources: MS Kinect for Xbox 360 John C. Tang. Using Kinect to explore NUI, Ms Research, From Stanford CS247 Shotton et al. Real-Time
Robot Mapping. SLAM Front-Ends. Cyrill Stachniss. Partial image courtesy: Edwin Olson 1
 Robot Mapping SLAM Front-Ends Cyrill Stachniss Partial image courtesy: Edwin Olson 1 Graph-Based SLAM Constraints connect the nodes through odometry and observations Robot pose Constraint 2 Graph-Based
Robot Mapping SLAM Front-Ends Cyrill Stachniss Partial image courtesy: Edwin Olson 1 Graph-Based SLAM Constraints connect the nodes through odometry and observations Robot pose Constraint 2 Graph-Based
Articulated Pose Estimation with Flexible Mixtures-of-Parts
 Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Articulated Pose Estimation with Flexible Mixtures-of-Parts PRESENTATION: JESSE DAVIS CS 3710 VISUAL RECOGNITION Outline Modeling Special Cases Inferences Learning Experiments Problem and Relevance Problem:
Towards Semantic Scene Analysis with Time-of-Flight Cameras
 Towards Semantic Scene Analysis with Time-of-Flight Cameras Dirk Holz 1, Ruwen Schnabel 2, David Droeschel 1, Jörg Stückler 1, and Sven Behnke 1 1 University of Bonn, Institute of Computer Science VI,
Towards Semantic Scene Analysis with Time-of-Flight Cameras Dirk Holz 1, Ruwen Schnabel 2, David Droeschel 1, Jörg Stückler 1, and Sven Behnke 1 1 University of Bonn, Institute of Computer Science VI,
Data-driven Depth Inference from a Single Still Image
 Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Data-driven Depth Inference from a Single Still Image Kyunghee Kim Computer Science Department Stanford University kyunghee.kim@stanford.edu Abstract Given an indoor image, how to recover its depth information
Scanning and Printing Objects in 3D Jürgen Sturm
 Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
Scanning and Printing Objects in 3D Jürgen Sturm Metaio (formerly Technical University of Munich) My Research Areas Visual navigation for mobile robots RoboCup Kinematic Learning Articulated Objects Quadrocopters
Computer Vision: Making machines see
 Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Computer Vision: Making machines see Roberto Cipolla Department of Engineering http://www.eng.cam.ac.uk/~cipolla/people.html http://www.toshiba.eu/eu/cambridge-research- Laboratory/ Vision: what is where
Dynamic Time Warping for Binocular Hand Tracking and Reconstruction
 Dynamic Time Warping for Binocular Hand Tracking and Reconstruction Javier Romero, Danica Kragic Ville Kyrki Antonis Argyros CAS-CVAP-CSC Dept. of Information Technology Institute of Computer Science KTH,
Dynamic Time Warping for Binocular Hand Tracking and Reconstruction Javier Romero, Danica Kragic Ville Kyrki Antonis Argyros CAS-CVAP-CSC Dept. of Information Technology Institute of Computer Science KTH,
Lecture 7: Semantic Segmentation
 Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Semantic Segmentation CSED703R: Deep Learning for Visual Recognition (207F) Segmenting images based on its semantic notion Lecture 7: Semantic Segmentation Bohyung Han Computer Vision Lab. bhhanpostech.ac.kr
Deep Incremental Scene Understanding. Federico Tombari & Christian Rupprecht Technical University of Munich, Germany
 Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Deep Incremental Scene Understanding Federico Tombari & Christian Rupprecht Technical University of Munich, Germany C. Couprie et al. "Toward Real-time Indoor Semantic Segmentation Using Depth Information"
Separating Objects and Clutter in Indoor Scenes
 Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Separating Objects and Clutter in Indoor Scenes Salman H. Khan School of Computer Science & Software Engineering, The University of Western Australia Co-authors: Xuming He, Mohammed Bennamoun, Ferdous
Dense Tracking and Mapping for Autonomous Quadrocopters. Jürgen Sturm
 Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Computer Vision Group Prof. Daniel Cremers Dense Tracking and Mapping for Autonomous Quadrocopters Jürgen Sturm Joint work with Frank Steinbrücker, Jakob Engel, Christian Kerl, Erik Bylow, and Daniel Cremers
Indoor Home Furniture Detection with RGB-D Data for Service Robots
 Indoor Home Furniture Detection with RGB-D Data for Service Robots Oscar Alonso-Ramirez 1, Antonio Marin-Hernandez 1, Michel Devy 2 and Fernando M. Montes-Gonzalez 1. Abstract Home furniture detection
Indoor Home Furniture Detection with RGB-D Data for Service Robots Oscar Alonso-Ramirez 1, Antonio Marin-Hernandez 1, Michel Devy 2 and Fernando M. Montes-Gonzalez 1. Abstract Home furniture detection
Finding Surface Correspondences With Shape Analysis
 Finding Surface Correspondences With Shape Analysis Sid Chaudhuri, Steve Diverdi, Maciej Halber, Vladimir Kim, Yaron Lipman, Tianqiang Liu, Wilmot Li, Niloy Mitra, Elena Sizikova, Thomas Funkhouser Motivation
Finding Surface Correspondences With Shape Analysis Sid Chaudhuri, Steve Diverdi, Maciej Halber, Vladimir Kim, Yaron Lipman, Tianqiang Liu, Wilmot Li, Niloy Mitra, Elena Sizikova, Thomas Funkhouser Motivation
Deep Learning for Robust Normal Estimation in Unstructured Point Clouds. Alexandre Boulch. Renaud Marlet
 Deep Learning for Robust Normal Estimation in Unstructured Point Clouds Alexandre Boulch Renaud Marlet Normal estimation in point clouds Normal: 3D normalized vector At each point: local orientation of
Deep Learning for Robust Normal Estimation in Unstructured Point Clouds Alexandre Boulch Renaud Marlet Normal estimation in point clouds Normal: 3D normalized vector At each point: local orientation of
Deep Learning for Remote Sensing
 1 ENPC Data Science Week Deep Learning for Remote Sensing Alexandre Boulch 2 ONERA Research, Innovation, expertise and long-term vision for industry, French government and Europe 3 Materials Optics Aerodynamics
1 ENPC Data Science Week Deep Learning for Remote Sensing Alexandre Boulch 2 ONERA Research, Innovation, expertise and long-term vision for industry, French government and Europe 3 Materials Optics Aerodynamics
Real-Time Human Pose Recognition in Parts from Single Depth Images
 Real-Time Human Pose Recognition in Parts from Single Depth Images Jamie Shotton, Andrew Fitzgibbon, Mat Cook, Toby Sharp, Mark Finocchio, Richard Moore, Alex Kipman, Andrew Blake CVPR 2011 PRESENTER:
Real-Time Human Pose Recognition in Parts from Single Depth Images Jamie Shotton, Andrew Fitzgibbon, Mat Cook, Toby Sharp, Mark Finocchio, Richard Moore, Alex Kipman, Andrew Blake CVPR 2011 PRESENTER:
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks
 Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Deep Tracking: Biologically Inspired Tracking with Deep Convolutional Networks Si Chen The George Washington University sichen@gwmail.gwu.edu Meera Hahn Emory University mhahn7@emory.edu Mentor: Afshin
Analysis: TextonBoost and Semantic Texton Forests. Daniel Munoz Februrary 9, 2009
 Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Analysis: TextonBoost and Semantic Texton Forests Daniel Munoz 16-721 Februrary 9, 2009 Papers [shotton-eccv-06] J. Shotton, J. Winn, C. Rother, A. Criminisi, TextonBoost: Joint Appearance, Shape and Context
Tri-modal Human Body Segmentation
 Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Tri-modal Human Body Segmentation Master of Science Thesis Cristina Palmero Cantariño Advisor: Sergio Escalera Guerrero February 6, 2014 Outline 1 Introduction 2 Tri-modal dataset 3 Proposed baseline 4
Learning and Recognizing Visual Object Categories Without First Detecting Features
 Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Learning and Recognizing Visual Object Categories Without First Detecting Features Daniel Huttenlocher 2007 Joint work with D. Crandall and P. Felzenszwalb Object Category Recognition Generic classes rather
Building Reliable 2D Maps from 3D Features
 Building Reliable 2D Maps from 3D Features Dipl. Technoinform. Jens Wettach, Prof. Dr. rer. nat. Karsten Berns TU Kaiserslautern; Robotics Research Lab 1, Geb. 48; Gottlieb-Daimler- Str.1; 67663 Kaiserslautern;
Building Reliable 2D Maps from 3D Features Dipl. Technoinform. Jens Wettach, Prof. Dr. rer. nat. Karsten Berns TU Kaiserslautern; Robotics Research Lab 1, Geb. 48; Gottlieb-Daimler- Str.1; 67663 Kaiserslautern;
Object Class and Instance Recognition on RGB-D Data
 Object Class and Instance Recognition on RGB-D Data Viktor Seib, Susanne Christ-Friedmann, Susanne Thierfelder, Dietrich Paulus Active Vision Group (AGAS), University of Koblenz-Landau Universitätsstr.
Object Class and Instance Recognition on RGB-D Data Viktor Seib, Susanne Christ-Friedmann, Susanne Thierfelder, Dietrich Paulus Active Vision Group (AGAS), University of Koblenz-Landau Universitätsstr.
3D Face and Hand Tracking for American Sign Language Recognition
 3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
3D Face and Hand Tracking for American Sign Language Recognition NSF-ITR (2004-2008) D. Metaxas, A. Elgammal, V. Pavlovic (Rutgers Univ.) C. Neidle (Boston Univ.) C. Vogler (Gallaudet) The need for automated
Tracking People. Tracking People: Context
 Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Tracking People A presentation of Deva Ramanan s Finding and Tracking People from the Bottom Up and Strike a Pose: Tracking People by Finding Stylized Poses Tracking People: Context Motion Capture Surveillance
Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning
 Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
Allan Zelener Dissertation Proposal December 12 th 2016 Object Localization, Segmentation, Classification, and Pose Estimation in 3D Images using Deep Learning Overview 1. Introduction to 3D Object Identification
3D Shape Segmentation with Projective Convolutional Networks
 3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
3D Shape Segmentation with Projective Convolutional Networks Evangelos Kalogerakis 1 Melinos Averkiou 2 Subhransu Maji 1 Siddhartha Chaudhuri 3 1 University of Massachusetts Amherst 2 University of Cyprus
Registration of Dynamic Range Images
 Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
Registration of Dynamic Range Images Tan-Chi Ho 1,2 Jung-Hong Chuang 1 Wen-Wei Lin 2 Song-Sun Lin 2 1 Department of Computer Science National Chiao-Tung University 2 Department of Applied Mathematics National
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material
 DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
DeepIM: Deep Iterative Matching for 6D Pose Estimation - Supplementary Material Yi Li 1, Gu Wang 1, Xiangyang Ji 1, Yu Xiang 2, and Dieter Fox 2 1 Tsinghua University, BNRist 2 University of Washington
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus
 Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture David Eigen, Rob Fergus Presented by: Rex Ying and Charles Qi Input: A Single RGB Image Estimate
Simultaneous Localization and Mapping (SLAM)
") Simultaneous Localization and Mapping (SLAM) RSS Lecture 16 April 8, 2013 Prof. Teller Text: Siegwart and Nourbakhsh S. 5.8 SLAM Problem Statement Inputs: No external coordinate reference Time series of
Simultaneous Localization and Mapping (SLAM) RSS Lecture 16 April 8, 2013 Prof. Teller Text: Siegwart and Nourbakhsh S. 5.8 SLAM Problem Statement Inputs: No external coordinate reference Time series of
arxiv: v1 [cs.cv] 31 Mar 2016
![arxiv: v1 [cs.cv] 31 Mar 2016](/thumbs/92/108399479.jpg "arxiv: v1 [cs.cv] 31 Mar 2016") Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Object Boundary Guided Semantic Segmentation Qin Huang, Chunyang Xia, Wenchao Zheng, Yuhang Song, Hao Xu and C.-C. Jay Kuo arxiv:1603.09742v1 [cs.cv] 31 Mar 2016 University of Southern California Abstract.
Scenario/Motivation. Introduction System Overview Surface Estimation Geometric Category and Model Applications Conclusions
 Single View Categorization and Modelling Nico Blodow, Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München IROS 2010 Workshop on Defining
Single View Categorization and Modelling Nico Blodow, Zoltan-Csaba Marton, Dejan Pangercic, Michael Beetz Intelligent Autonomous Systems Group Technische Universität München IROS 2010 Workshop on Defining
INTELLIGENT AUTONOMOUS SYSTEMS LAB
 Matteo Munaro 1,3, Alex Horn 2, Randy Illum 2, Jeff Burke 2, and Radu Bogdan Rusu 3 1 IAS-Lab at Department of Information Engineering, University of Padova 2 Center for Research in Engineering, Media
Matteo Munaro 1,3, Alex Horn 2, Randy Illum 2, Jeff Burke 2, and Radu Bogdan Rusu 3 1 IAS-Lab at Department of Information Engineering, University of Padova 2 Center for Research in Engineering, Media
3D Scanning. Qixing Huang Feb. 9 th Slide Credit: Yasutaka Furukawa
 3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
3D Scanning Qixing Huang Feb. 9 th 2017 Slide Credit: Yasutaka Furukawa Geometry Reconstruction Pipeline This Lecture Depth Sensing ICP for Pair-wise Alignment Next Lecture Global Alignment Pairwise Multiple
Object Detection. CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR
 Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
Object Detection CS698N Final Project Presentation AKSHAT AGARWAL SIDDHARTH TANWAR Problem Description Arguably the most important part of perception Long term goals for object recognition: Generalization
ECE 6554:Advanced Computer Vision Pose Estimation
 ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
ECE 6554:Advanced Computer Vision Pose Estimation Sujay Yadawadkar, Virginia Tech, Agenda: Pose Estimation: Part Based Models for Pose Estimation Pose Estimation with Convolutional Neural Networks (Deep
RGB-D Object Recognition and Pose Estimation based on Pre-trained Convolutional Neural Network Features
 RGB-D Object Recognition and Pose Estimation based on Pre-trained Convolutional Neural Network Features Max Schwarz, Hannes Schulz, and Sven Behnke Abstract Object recognition and pose estimation from
RGB-D Object Recognition and Pose Estimation based on Pre-trained Convolutional Neural Network Features Max Schwarz, Hannes Schulz, and Sven Behnke Abstract Object recognition and pose estimation from
CURFIL: A GPU library for Image Labeling with Random Forests
 CURFIL: A GPU library for Image Labeling with Random Forests Hannes Schulz, Benedikt Waldvogel, Rasha Sheikh, and Sven Behnke University of Bonn, Computer Science Institute VI Autonomous Intelligent Systems
CURFIL: A GPU library for Image Labeling with Random Forests Hannes Schulz, Benedikt Waldvogel, Rasha Sheikh, and Sven Behnke University of Bonn, Computer Science Institute VI Autonomous Intelligent Systems
IN computer vision develop mathematical techniques in
 International Journal of Scientific & Engineering Research Volume 4, Issue3, March-2013 1 Object Tracking Based On Tracking-Learning-Detection Rupali S. Chavan, Mr. S.M.Patil Abstract -In this paper; we
International Journal of Scientific & Engineering Research Volume 4, Issue3, March-2013 1 Object Tracking Based On Tracking-Learning-Detection Rupali S. Chavan, Mr. S.M.Patil Abstract -In this paper; we
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model
 Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
Object Segmentation and Tracking in 3D Video With Sparse Depth Information Using a Fully Connected CRF Model Ido Ofir Computer Science Department Stanford University December 17, 2011 Abstract This project
Learning to Segment Object Candidates
 Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Learning to Segment Object Candidates Pedro Pinheiro, Ronan Collobert and Piotr Dollar Presented by - Sivaraman, Kalpathy Sitaraman, M.S. in Computer Science, University of Virginia Facebook Artificial
Human Upper Body Pose Estimation in Static Images
 1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
1. Research Team Human Upper Body Pose Estimation in Static Images Project Leader: Graduate Students: Prof. Isaac Cohen, Computer Science Mun Wai Lee 2. Statement of Project Goals This goal of this project
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach
 Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Human Detection and Tracking for Video Surveillance: A Cognitive Science Approach Vandit Gajjar gajjar.vandit.381@ldce.ac.in Ayesha Gurnani gurnani.ayesha.52@ldce.ac.in Yash Khandhediya khandhediya.yash.364@ldce.ac.in
Removing Moving Objects from Point Cloud Scenes
 Removing Moving Objects from Point Cloud Scenes Krystof Litomisky and Bir Bhanu University of California, Riverside krystof@litomisky.com, bhanu@ee.ucr.edu Abstract. Three-dimensional simultaneous localization
Removing Moving Objects from Point Cloud Scenes Krystof Litomisky and Bir Bhanu University of California, Riverside krystof@litomisky.com, bhanu@ee.ucr.edu Abstract. Three-dimensional simultaneous localization
CS 4495 Computer Vision A. Bobick. Motion and Optic Flow. Stereo Matching
 Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
What Happened to the Representations of Perception? Cornelia Fermüller Computer Vision Laboratory University of Maryland
 What Happened to the Representations of Perception? Cornelia Fermüller Computer Vision Laboratory University of Maryland Why we study manipulation actions? 2. Learning from humans to teach robots Y Yang,
What Happened to the Representations of Perception? Cornelia Fermüller Computer Vision Laboratory University of Maryland Why we study manipulation actions? 2. Learning from humans to teach robots Y Yang,
A THREE LAYERED MODEL TO PERFORM CHARACTER RECOGNITION FOR NOISY IMAGES
 INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONSAND ROBOTICS ISSN 2320-7345 A THREE LAYERED MODEL TO PERFORM CHARACTER RECOGNITION FOR NOISY IMAGES 1 Neha, 2 Anil Saroliya, 3 Varun Sharma 1,
INTERNATIONAL JOURNAL OF RESEARCH IN COMPUTER APPLICATIONSAND ROBOTICS ISSN 2320-7345 A THREE LAYERED MODEL TO PERFORM CHARACTER RECOGNITION FOR NOISY IMAGES 1 Neha, 2 Anil Saroliya, 3 Varun Sharma 1,
Large-Scale Point Cloud Classification Benchmark
 Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
Large-Scale Point Cloud Classification Benchmark www.semantic3d.net IGP & CVG, ETH Zürich www.semantic3d.net, info@semantic3d.net 7/6/2016 1 Timo Hackel Nikolay Savinov Ľubor Ladický Jan Dirk Wegner Konrad
Chapter 3 Image Registration. Chapter 3 Image Registration
 Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Chapter 3 Image Registration Distributed Algorithms for Introduction (1) Definition: Image Registration Input: 2 images of the same scene but taken from different perspectives Goal: Identify transformation
Visual Recognition and Search April 18, 2008 Joo Hyun Kim
 Visual Recognition and Search April 18, 2008 Joo Hyun Kim Introduction Suppose a stranger in downtown with a tour guide book?? Austin, TX 2 Introduction Look at guide What s this? Found Name of place Where
Visual Recognition and Search April 18, 2008 Joo Hyun Kim Introduction Suppose a stranger in downtown with a tour guide book?? Austin, TX 2 Introduction Look at guide What s this? Found Name of place Where
BSB663 Image Processing Pinar Duygulu. Slides are adapted from Selim Aksoy
 BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
BSB663 Image Processing Pinar Duygulu Slides are adapted from Selim Aksoy Image matching Image matching is a fundamental aspect of many problems in computer vision. Object or scene recognition Solving
3D Computer Vision. Depth Cameras. Prof. Didier Stricker. Oliver Wasenmüller
 3D Computer Vision Depth Cameras Prof. Didier Stricker Oliver Wasenmüller Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
3D Computer Vision Depth Cameras Prof. Didier Stricker Oliver Wasenmüller Kaiserlautern University http://ags.cs.uni-kl.de/ DFKI Deutsches Forschungszentrum für Künstliche Intelligenz http://av.dfki.de
3D Terrain Sensing System using Laser Range Finder with Arm-Type Movable Unit
 3D Terrain Sensing System using Laser Range Finder with Arm-Type Movable Unit 9 Toyomi Fujita and Yuya Kondo Tohoku Institute of Technology Japan 1. Introduction A 3D configuration and terrain sensing
3D Terrain Sensing System using Laser Range Finder with Arm-Type Movable Unit 9 Toyomi Fujita and Yuya Kondo Tohoku Institute of Technology Japan 1. Introduction A 3D configuration and terrain sensing
Indoor Object Recognition of 3D Kinect Dataset with RNNs
 Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Indoor Object Recognition of 3D Kinect Dataset with RNNs Thiraphat Charoensripongsa, Yue Chen, Brian Cheng 1. Introduction Recent work at Stanford in the area of scene understanding has involved using
Learning from 3D Data
 Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Learning from 3D Data Thomas Funkhouser Princeton University* * On sabbatical at Stanford and Google Disclaimer: I am talking about the work of these people Shuran Song Andy Zeng Fisher Yu Yinda Zhang
Automatic Photo Popup
 Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
Automatic Photo Popup Derek Hoiem Alexei A. Efros Martial Hebert Carnegie Mellon University What Is Automatic Photo Popup Introduction Creating 3D models from images is a complex process Time-consuming
3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field
 07 5th European Signal Processing Conference (EUSIPCO) 3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Josep R.Casas Montse Pardás Abstract Traditional image segmentation
07 5th European Signal Processing Conference (EUSIPCO) 3D Point Cloud Segmentation Using a Fully Connected Conditional Random Field Xiao Lin Josep R.Casas Montse Pardás Abstract Traditional image segmentation
Robotics Programming Laboratory
 Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
Chair of Software Engineering Robotics Programming Laboratory Bertrand Meyer Jiwon Shin Lecture 8: Robot Perception Perception http://pascallin.ecs.soton.ac.uk/challenges/voc/databases.html#caltech car
CS 4495 Computer Vision A. Bobick. Motion and Optic Flow. Stereo Matching
 Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
Stereo Matching Fundamental matrix Let p be a point in left image, p in right image l l Epipolar relation p maps to epipolar line l p maps to epipolar line l p p Epipolar mapping described by a 3x3 matrix
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE
 SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
SIMPLE ROOM SHAPE MODELING WITH SPARSE 3D POINT INFORMATION USING PHOTOGRAMMETRY AND APPLICATION SOFTWARE S. Hirose R&D Center, TOPCON CORPORATION, 75-1, Hasunuma-cho, Itabashi-ku, Tokyo, Japan Commission
Kinect Device. How the Kinect Works. Kinect Device. What the Kinect does 4/27/16. Subhransu Maji Slides credit: Derek Hoiem, University of Illinois
 4/27/16 Kinect Device How the Kinect Works T2 Subhransu Maji Slides credit: Derek Hoiem, University of Illinois Photo frame-grabbed from: http://www.blisteredthumbs.net/2010/11/dance-central-angry-review
4/27/16 Kinect Device How the Kinect Works T2 Subhransu Maji Slides credit: Derek Hoiem, University of Illinois Photo frame-grabbed from: http://www.blisteredthumbs.net/2010/11/dance-central-angry-review
Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling
 [DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
[DOI: 10.2197/ipsjtcva.7.99] Express Paper Cost-alleviative Learning for Deep Convolutional Neural Network-based Facial Part Labeling Takayoshi Yamashita 1,a) Takaya Nakamura 1 Hiroshi Fukui 1,b) Yuji
Structured Models in. Dan Huttenlocher. June 2010
 Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Structured Models in Computer Vision i Dan Huttenlocher June 2010 Structured Models Problems where output variables are mutually dependent or constrained E.g., spatial or temporal relations Such dependencies
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun Presented by Tushar Bansal Objective 1. Get bounding box for all objects
Interactive Collision Detection for Engineering Plants based on Large-Scale Point-Clouds
 1 Interactive Collision Detection for Engineering Plants based on Large-Scale Point-Clouds Takeru Niwa 1 and Hiroshi Masuda 2 1 The University of Electro-Communications, takeru.niwa@uec.ac.jp 2 The University
1 Interactive Collision Detection for Engineering Plants based on Large-Scale Point-Clouds Takeru Niwa 1 and Hiroshi Masuda 2 1 The University of Electro-Communications, takeru.niwa@uec.ac.jp 2 The University