Computer Architecture
|
|
|
- Myron Reynolds
- 6 years ago
- Views:
Transcription
1 Compter Architectre Lectre 4: Intro to icroarchitectre: Single- Cycle Dr. Ahmed Sallam Sez Canal University Based on original slides by Prof. Onr tl
2 Review Compter Architectre Today and Basics (Lectres ) Fndamental Concepts (Lectre 2) ISA basics and tradeoffs (Lectres 3) Last Lectre: ISA tradeoffs contined length Uniform vs. non-niform decode Nmber of registers Addressing modes Aligned vs. naligned access RISC vs. CISC properties 2
3 icroarchitectre will cover the following Start icroarchitectre Single-cycle icroarchitectres lti-cycle icroarchitectres icroprogrammed icroarchitectres Pipelining Isses in Pipelining: Control & Data Dependence Handling, State aintenance and Recovery, 3
4 Implementing the ISA: icroarchitectre Basics 4
5 Processing Cycle s are processed nder the direction of a control nit step by step. cycle: Seqence of steps to process an instrction Fndamentally, there are si phases: Fetch Decode Evalate Address Fetch Operands Eecte Store Reslt Not all instrctions reqire all si stages (see P&P Ch. 4) 5
6 How Does a achine Process s? What does processing an instrction mean? Remember the von Nemann model AS = Architectral (programmer visible) state before an instrction is processed Process instrction AS = Architectral (programmer visible) state after an instrction is processed Processing an instrction: Transforming AS to AS according to the ISA specification of the instrction 6
7 Processing Cycle vs. achine Clock Cycle Single-cycle machine: All si phases of the instrction processing cycle take a single machine clock cycle to complete lti-cycle machine: All si phases of the instrction processing cycle can take mltiple machine clock cycles to complete In fact, each phase can take mltiple clock cycles to complete 7
8 How the processor fnction 8
9 Single-cycle vs. lti-cycle achines Single-cycle machines Each instrction takes a single clock cycle All state pdates made at the end of an instrction s eection Big disadvantage: The slowest instrction determines cycle time long clock cycle time lti-cycle machines processing broken into mltiple cycles/stages State pdates can be made dring an instrction s eection Architectral state pdates made only at the end of an instrction s eection Advantage over single-cycle: The slowest stage determines cycle time Both single-cycle and mlti-cycle machines literally follow the von Nemann model at the microarchitectre level 9
10 Processing Viewed Another Way s transform Data (AS) to Data (AS ) This transformation is done by fnctional nits Units that operate on These nits need to be told what to do to the An instrction processing engine consists of two components Datapath: Consists of hardware elements that deal with and transform signals fnctional nits that operate on hardware strctres (e.g. wires and mes) that enable the flow of into the fnctional nits and registers storage nits that store (e.g., registers) Control logic: Consists of hardware elements that determine control signals, i.e., signals that specify what the path elements shold do to the
11 Single-cycle vs. lti-cycle: Control & Data Single-cycle machine: Control signals are generated in the same clock cycle as the one dring which signals are operated on Everything related to an instrction happens in one clock cycle (serialized processing) lti-cycle machine: Control signals needed in the net cycle can be generated in the crrent cycle Latency of control processing can be overlapped with latency of path operation (more parallelism)
12 Flash-Forward: Performance Analysis Eection time of an instrction {CPI} {clock cycle time} Eection time of a program Sm over all instrctions [{CPI} {clock cycle time}] {# of instrctions} {Average CPI} {clock cycle time} Single cycle microarchitectre performance CPI = Clock cycle time = long lti-cycle microarchitectre performance CPI = different for each instrction Average CPI hopeflly small Clock cycle time = short Now, we have two degrees of freedom to optimize independently 2
13 A Single-Cycle icroarchitectre A Closer Look 3
14 Remember Single-cycle machine Combinational Logic AS Seqential Logic (State) AS 4
15 Let s Start with the State Elements Data and control inpts PC register register 2 Registers register 2 Reg em address memory Address Data memory em **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 5
16 For Now, We Will Assme agic memory and register file Combinational read otpt of the read port is a combinational fnction of the register file contents and the corresponding read select port Synchronos write the selected register is pdated on the positive edge clock transition when write enable is asserted Cannot affect read otpt in between clock edges Single-cycle, synchronos memory Contrast this with memory that tells when the is ready i.e., y bit: indicating the read or write is done 6
17 Processing 5 generic steps (P&H book) IF fetch (IF) decode and register operand fetch (ID/RF) Eecte/emory address generation (EX/AG) emory operand fetch (E) Store/writeback reslt (WB) Data Register # PC Address Registers ALU Register # memory ID/RF Register # EX/AG WB Address Data Data memory E **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 7
18 What Is To Come: The Fll IPS Datapath [25 ] Shift Jmp address [3 ] left PCSrc =Jmp 4 Add PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory [25 2] [2 6] [5 ] register register 2 Registers 2 register bcond Zero ALU ALU reslt Address Data memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] JAL, JR, JALR omitted 8
19 Single-Cycle Datapath for Arithmetic and Logical s 9
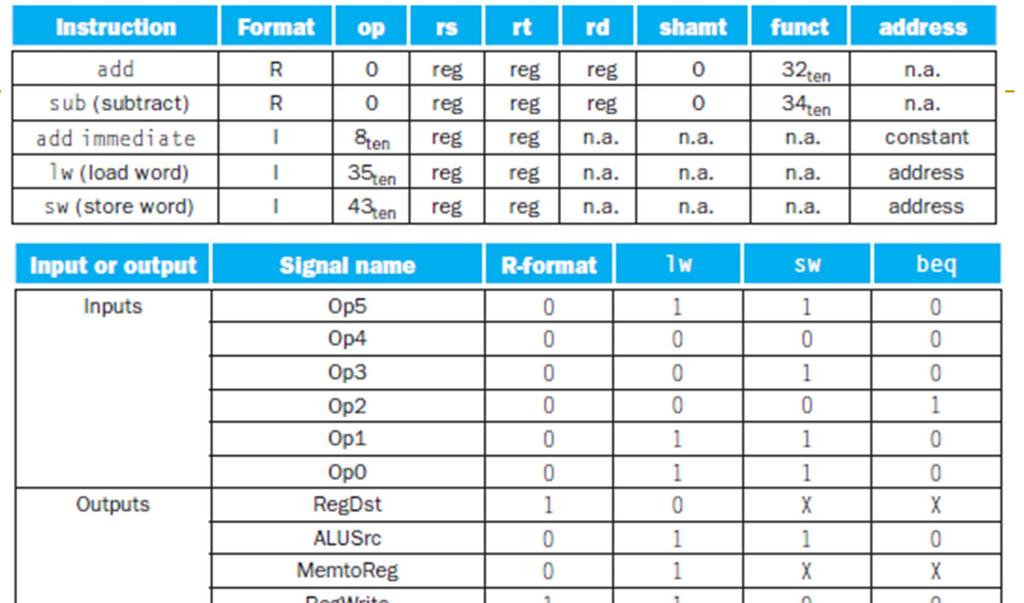
20 R-Type ALU s Assembly (e.g., register-register signed addition) ADD rd reg rs reg rt reg achine encoding 3-26 ADD 6 bit 25-2 rs 5 bit 2-6 rt 5 bit 5- rd 5 bit -6 shamt 5 bit 5- fnct 6 bit R type Semantics if E[PC] == ADD rd rs rt GPR[rd] GPR[rs] + GPR[rt] PC PC + 4 2
21 ALU Datapath Add 4 PC address memory 25:2 2:6 5: register register 2 Registers register 2 3 ALU operation Zero ALU ALU reslt Reg if E[PC] == ADD rd rs rt GPR[rd] GPR[rs] + GPR[rt] PC PC + 4 **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] IF ID EX E WB Combinational state pdate logic 2
22 Apply R - Type if E[PC] == ADD rd rs rt GPR[rd] GPR[rs] + GPR[rt] PC PC + 4 Add 4 Sign 6 Etend 32 PC Address Reg emory Reg Reg RS Data RT Registers RD Data 2 Data ALUop ALU U X Address Data Data emory Data Reg Reg 22
23 I-Type ALU s Assembly (e.g., register-immediate signed additions) ADDI rt reg rs reg immediate 6 achine encoding 3-26 ADDI 6-bit 25-2 rs 5-bit 2-6 rt 5-bit 5- immediate 6-bit I-type Semantics if E[PC] == ADDI rt rs immediate GPR[rt] GPR[rs] + sign-etend (immediate) PC PC
24 Apply I - Type if E[PC] == ADDI rt rs immediate GPR[rt] GPR[rs] + sign-etend (immediate) PC PC
25 Datapath for R and I-Type ALU Insts. Add 4 PC address memory 25:2 2:6 5: RegDest isitype register register 2 Registers register Reg 2 6 Sign 32 etend 3 ALUSrc isitype ALU operatio Zero ALU ALU reslt if E[PC] == ADDI rt rs immediate GPR[rt] GPR[rs] + sign etend (immediate) PC PC + 4 **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] IF ID EX E WB Combinational state pdate logic 25
26 Single-Cycle Datapath for Data ovement s 26
27 Load s Assembly (e.g., load 4-byte word) LW rt reg offset 6 (base reg ) achine encoding LW 6 bit base 5 bit rt 5 bit offset 6 bit I type Semantics if E[PC]==LW rt offset 6 (base) EA = sign-etend(offset) + GPR[base] GPR[rt] E[ translate(ea) ] PC PC
28 LW Datapath PC address memory 4 Add RegDest isitype register register 2 Registers register Reg 2 6 Sign 32 etend add 3 ALU operatio Zero ALU ALU reslt ALUSrc isitype Address em Data memory em if E[PC]==LW rt offset 6 (base) EA = sign etend(offset) + GPR[base] GPR[rt] E[ translate(ea) ] PC PC + 4 IF ID EX E WB Combinational state pdate logic 28
29 Apply LW if E[PC] == ADDI rt rs immediate GPR[rt] GPR[rs] + sign-etend (immediate) PC PC + 4 Add 4 Reg Reg PC Address emory U X RS Data RT Registers RD Data 2 Data ALUop ALU Address Data Data emory Data Reg Sign 6 Etend 32 29
30 Store s Assembly (e.g., store 4-byte word) SW rt reg offset 6 (base reg ) achine encoding SW 6 bit base 5 bit rt 5 bit offset 6 bit I type Semantics if E[PC]==SW rt offset 6 (base) EA = sign-etend(offset) + GPR[base] E[ translate(ea) ] GPR[rt] PC PC + 4 3
31 SW Datapath PC address memory 4 Add RegDest isitype register register 2 Registers register Reg 2 6 Sign 32 etend add 3 ALUSrc isitype ALU operatio Zero ALU ALU reslt Address em Data memory em if E[PC]==SW rt offset 6 (base) EA = sign etend(offset) + GPR[base] E[ translate(ea) ] GPR[rt] PC PC + 4 IF ID EX E WB Combinational state pdate logic 3
32 Apply LW Add ALUop ALU Sign 6 Etend 32 Reg 4 PC U X RS Data RT Registers RD Data 2 Data Reg Address emory Address Data Data emory Data Reg 32
33 Load-Store Datapath Add PC address memory 4 RegDest isitype register register 2 Registers register Reg!isStore 2 6 Sign 32 etend add 3 Zero ALU ALU reslt ALUSrc isitype ALU operation Address isstore em Data memory isload em **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 33
34 Datapath for (Non-Control-Flow) Insts. Add PC address memory 4 RegDest isitype register register 2 Registers register Reg!isStore 2 6 Sign 32 etend 3 Zero ALU ALU reslt ALUSrc isitype ALU operation Address isstore em Data memory isload em emtoreg isload **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 34
35 Single-Cycle Datapath for Control Flow s 35
36 Unconditional Jmp s Assembly J immediate 26 achine encoding J 6 bit immediate 26 bit J type Semantics if E[PC]==J immediate 26 target = { PC[3:28], immediate 26, 2 b } PC target 36
37 Unconditional Jmp Datapath isj PCSrc concat PC address memory 4 **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] Add? register register 2 Registers register Reg 2 6 Sign 32 etend X 3 X ALU operation Zero ALU ALU reslt ALUSrc Address em Data memory em if E[PC]==J immediate26 PC ={ PC[3:28], immediate26, 2 b } What abot JR, JAL, JALR? 37
38 Aside: IPS Cheat Sheet edia=mips_reference_.pdf Looks like! 38
39 Conditional Branch s Assembly (e.g., branch if eqal) BEQ rs reg rt reg immediate 6 achine encoding BEQ 6 bit rs 5 bit rt 5 bit immediate 6 bit I type Semantics (assming no branch delay slot) if E[PC]==BEQ rs rt immediate 6 target = PC sign-etend(immediate) 4 if GPR[rs]==GPR[rt] then PC target else PC PC
40 Conditional Branch Datapath (for yo to finish) watch ot PCSrc concat PC address memory 4 Add PC + 4 from instrction path register register 2 Registers register 2 Shift left 2 Add sb 3 Sm ALU operation ALU bcond Zero Branch target To branch control logic Reg 6 Sign 32 etend **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] How to phold the delayed branch semantics? 4
41 Ptting It All Together [25 ] Shift Jmp address [3 ] left PCSrc =Jmp 4 Add PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory [25 2] [2 6] [5 ] register register 2 Registers 2 register bcond Zero ALU ALU reslt Address Data memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] JAL, JR, JALR omitted 4
42 Single-Cycle Control Logic 42
43 Single-Cycle Hardwired Control As combinational fnction of Inst=E[PC] 3 opcode 6 bit 3 3 opcode 6 bit opcode 6 bit rs 5 bit rs 5 bit 2 2 rt 5 bit rt 5 bit immediate 26 bit 6 6 rd 5 bit immediate 6 bit shamt 5 bit 6 fnct 6 bit R type I type J type Consider All R-type and I-type ALU instrctions LW and SW BEQ, BNE, BLEZ, BGTZ J, JR, JAL, JALR 43
44 44


45 Single-Bit Control Signals JAL and JALR reqire additional RegDest and emtoreg options 45

46 ALU Control 46
47 ALU Control 47
48 R-Type ALU ADD rs rt rd
49 I-Type ALU ADD rs rt imm
50 LW lw base(rs), rt, imm
51 BEQ beq rs, rt, imm
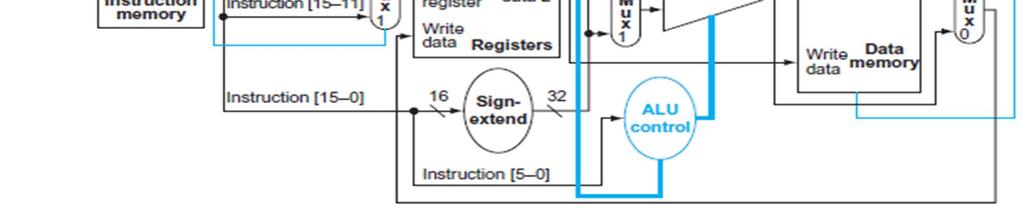
52 52
53 53
54 Jmp **Based on original figre from [P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.]

55 ALU Control 55
56 What is in That Control Bo? Combinational Logic Hardwired Control Idea: Control signals generated combinationally based on instrction Necessary in a single-cycle microarchitectre Seqential Logic Seqential/icroprogrammed Control Idea: A memory strctre contains the control signals associated with an instrction Control Store 56
57 Evalating the Single-Cycle icroarchitectre 57
58 A Single-Cycle icroarchitectre Is this a good idea/design? When is this a good design? When is this a bad design? How can we design a better microarchitectre? 58
59 A Single-Cycle icroarchitectre: Analysis Every instrction takes cycle to eecte CPI (Cycles per instrction) is strictly How long each instrction takes is determined by how long the slowest instrction takes to eecte Even thogh many instrctions do not need that long to eecte Clock cycle time of the microarchitectre is determined by how long it takes to complete the slowest instrction Critical path of the design is determined by the processing time of the slowest instrction 59
60 What is the Slowest to Process? Let s go back to the basics All si phases of the instrction processing cycle take a single machine clock cycle to complete Fetch Decode Evalate Address Fetch Operands Eecte Store Reslt. fetch (IF) 2. decode and register operand fetch (ID/RF) 3. Eecte/Evalate memory address (EX/AG) 4. emory operand fetch (E) 5. Store/writeback reslt (WB) Do each of the above phases take the same time (latency) for all instrctions? 6
61 Single-Cycle Datapath Analysis Assme memory nits (read or write): 2 ps ALU and adders: ps register file (read or write): 5 ps other combinational logic: ps steps IF ID EX E WB resorces em RF ALU mem RF Delay R type I type LW SW Branch Jmp 2 2 6
62 Let s Find the Critical Path [25 ] Shift Jmp address [3 ] left PCSrc =Jmp 4 Add PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory [25 2] [2 6] [5 ] register register 2 Registers 2 register bcond Zero ALU ALU reslt Address Data memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 62
63 R-Type and I-Type ALU [25 ] Shift Jmp address [3 ] left PCSrc =Jmp ps 4 Add ps PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory 2ps [25 2] [2 6] [5 ] register register 2 Registers 2 register 4ps 25ps bcond Zero ALU ALU reslt Address 35ps Data memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 63
64 LW [25 ] Shift Jmp address [3 ] left PCSrc =Jmp ps 4 Add ps PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory 2ps [25 2] [2 6] [5 ] register register 2 Registers 2 register 6ps 25ps bcond Zero ALU ALU reslt Address 35ps Data memory 55ps [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 64
65 SW [25 ] Shift Jmp address [3 ] left PCSrc =Jmp ps 4 Add ps PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory 2ps [25 2] [2 6] [5 ] register register 2 Registers 2 register 25ps bcond Zero ALU ALU reslt 35ps Address Data 55ps memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 65
66 Branch Taken 35ps PC 4 address Add [3 ] memory ps [25 ] Shift Jmp address [3 ] left ps PC+4 [3 28] [3 26] [25 2] [2 6] [5 ] [5 ] RegDst Jmp Branch em Control emtoreg ALUOp em ALUSrc Reg register register 2 Registers 2 register 6 Sign 32 etend Shift left 2 25ps ALU control 2ps Add ALU reslt bcond Zero ALU ALU reslt 35ps ALU operation Address PCSrc =Jmp Data memory PCSrc 2 =Br Taken [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 66
67 Jmp [25 ] Shift Jmp address [3 ] left PCSrc =Jmp 2ps 4 Add ps PC+4 [3 28] [3 26] Control RegDst Jmp Branch em emtoreg ALUOp em ALUSrc Reg Shift left 2 Add ALU reslt PCSrc 2 =Br Taken PC address [3 ] memory 2ps [25 2] [2 6] [5 ] register register 2 Registers 2 register bcond Zero ALU ALU reslt Address Data memory [5 ] 6 Sign 32 etend ALU control ALU operation [5 ] [Based on original figre from P&H CO&D, COPYRIGHT 24 Elsevier. ALL RIGHTS RESERVED.] 67
68 What Abot Control Logic? How does that affect the critical path? Think abot it!: Can control logic be on the critical path? A note on CDC 56: control store access too long 68
69 What is the Slowest to Process? emory is not magic What if memory sometimes takes ms to access? Does it make sense to have a simple register to register add or jmp to take {ms+all else to do a memory operation}? And, what if yo need to access memory more than once to process an instrction? Which instrctions need this? Do yo provide mltiple ports to memory? 69
70 Single Cycle Arch: Compleity Contrived All instrctions rn as slow as the slowest instrction Inefficient All instrctions rn as slow as the slowest instrction st provide worst-case combinational resorces in parallel as reqired by any instrction Need to replicate a resorce if it is needed more than once by an instrction dring different parts of the instrction processing cycle Not necessarily the simplest way to implement an ISA Single-cycle implementation of REP OVS (86) or INDEX (VAX)? Not easy to optimize/improve performance Optimizing the common case does not work (e.g. common instrctions) Need to optimize the worst case all the time 7
71 (icro)architectre Design Principles Critical path design Find and decrease the maimm combinational logic delay Break a path into mltiple cycles if it takes too long Bread and btter (common case) design Spend time and resorces on where it matters most i.e., improve what the machine is really designed to do Common case vs. ncommon case Balanced design Balance instrction/ flow throgh hardware components Design to eliminate bottlenecks: balance the hardware for the work 7
72 Single-Cycle Design vs. Design Principles Critical path design Bread and btter (common case) design Balanced design How does a single-cycle microarchitectre fare in light of these principles? 72
73 lti-cycle icroarchitectres 73
Computer Architecture
 Compter Architectre Lectre 4: Intro to icroarchitectre: Single- Cycle Dr. Ahmed Sallam Sez Canal University Spring 25 Based on original slides by Prof. Onr tl Review Compter Architectre Today and Basics
Compter Architectre Lectre 4: Intro to icroarchitectre: Single- Cycle Dr. Ahmed Sallam Sez Canal University Spring 25 Based on original slides by Prof. Onr tl Review Compter Architectre Today and Basics
Computer Architecture Lecture 6: Multi-cycle Microarchitectures. Prof. Onur Mutlu Carnegie Mellon University Spring 2012, 2/6/2012
 8-447 Compter Architectre Lectre 6: lti-cycle icroarchitectres Prof. Onr tl Carnegie ellon University Spring 22, 2/6/22 Reminder: Homeworks Homework soltions Check and stdy the soltions! Learning now is
8-447 Compter Architectre Lectre 6: lti-cycle icroarchitectres Prof. Onr tl Carnegie ellon University Spring 22, 2/6/22 Reminder: Homeworks Homework soltions Check and stdy the soltions! Learning now is
Lecture 6: Microprogrammed Multi Cycle Implementation. James C. Hoe Department of ECE Carnegie Mellon University
 8 447 Lectre 6: icroprogrammed lti Cycle Implementation James C. Hoe Department of ECE Carnegie ellon University 8 447 S8 L06 S, James C. Hoe, CU/ECE/CALC, 208 Yor goal today Hosekeeping nderstand why
8 447 Lectre 6: icroprogrammed lti Cycle Implementation James C. Hoe Department of ECE Carnegie ellon University 8 447 S8 L06 S, James C. Hoe, CU/ECE/CALC, 208 Yor goal today Hosekeeping nderstand why
Lecture 9: Microcontrolled Multi-Cycle Implementations
 8-447 Lectre 9: icroled lti-cycle Implementations James C. Hoe Dept of ECE, CU Febrary 8, 29 S 9 L9- Annoncements: P&H Appendi D Get started t on Lab Handots: Handot #8: Project (on Blackboard) Single-Cycle
8-447 Lectre 9: icroled lti-cycle Implementations James C. Hoe Dept of ECE, CU Febrary 8, 29 S 9 L9- Annoncements: P&H Appendi D Get started t on Lab Handots: Handot #8: Project (on Blackboard) Single-Cycle
CMSC Computer Architecture Lecture 4: Single-Cycle uarch and Pipelining. Prof. Yanjing Li University of Chicago
 CMSC 22200 Computer Architecture Lecture 4: Single-Cycle uarch and Pipelining Prof. Yanjing Li University of Chicago Administrative Stuff! Lab1 due at 11:59pm today! Lab2 out " Pipeline ARM simulator "
CMSC 22200 Computer Architecture Lecture 4: Single-Cycle uarch and Pipelining Prof. Yanjing Li University of Chicago Administrative Stuff! Lab1 due at 11:59pm today! Lab2 out " Pipeline ARM simulator "
Computer Architecture Chapter 5. Fall 2005 Department of Computer Science Kent State University
 Compter Architectre Chapter 5 Fall 25 Department of Compter Science Kent State University The Processor: Datapath & Control Or implementation of the MIPS is simplified memory-reference instrctions: lw,
Compter Architectre Chapter 5 Fall 25 Department of Compter Science Kent State University The Processor: Datapath & Control Or implementation of the MIPS is simplified memory-reference instrctions: lw,
Review. A single-cycle MIPS processor
 Review If three instrctions have opcodes, 7 and 5 are they all of the same type? If we were to add an instrction to IPS of the form OD $t, $t2, $t3, which performs $t = $t2 OD $t3, what wold be its opcode?
Review If three instrctions have opcodes, 7 and 5 are they all of the same type? If we were to add an instrction to IPS of the form OD $t, $t2, $t3, which performs $t = $t2 OD $t3, what wold be its opcode?
The final datapath. M u x. Add. 4 Add. Shift left 2. PCSrc. RegWrite. MemToR. MemWrite. Read data 1 I [25-21] Instruction. Read. register 1 Read.
![The final datapath. M u x. Add. 4 Add. Shift left 2. PCSrc. RegWrite. MemToR. MemWrite. Read data 1 I [25-21] Instruction. Read. register 1 Read.](/thumbs/77/75626003.jpg "The final datapath. M u x. Add. 4 Add. Shift left 2. PCSrc. RegWrite. MemToR. MemWrite. Read data 1 I [25-21] Instruction. Read. register 1 Read.") The final path PC 4 Add Reg Shift left 2 Add PCSrc Instrction [3-] Instrction I [25-2] I [2-6] I [5 - ] register register 2 register 2 Registers ALU Zero Reslt ALUOp em Data emtor RegDst ALUSrc em I [5
The final path PC 4 Add Reg Shift left 2 Add PCSrc Instrction [3-] Instrction I [25-2] I [2-6] I [5 - ] register register 2 register 2 Registers ALU Zero Reslt ALUOp em Data emtor RegDst ALUSrc em I [5
Computer Architecture. Lecture 6: Pipelining
 Compter Architectre Lectre 6: Pipelining Dr. Ahmed Sallam Based on original slides by Prof. Onr tl Agenda for Today & Net Few Lectres Single-cycle icroarchitectres lti-cycle and icroprogrammed icroarchitectres
Compter Architectre Lectre 6: Pipelining Dr. Ahmed Sallam Based on original slides by Prof. Onr tl Agenda for Today & Net Few Lectres Single-cycle icroarchitectres lti-cycle and icroprogrammed icroarchitectres
1048: Computer Organization
 48: Compter Organization Lectre 5 Datapath and Control Lectre5A - simple implementation (cwli@twins.ee.nct.ed.tw) 5A- Introdction In this lectre, we will try to implement simplified IPS which contain emory
48: Compter Organization Lectre 5 Datapath and Control Lectre5A - simple implementation (cwli@twins.ee.nct.ed.tw) 5A- Introdction In this lectre, we will try to implement simplified IPS which contain emory
Lecture 3: Single Cycle Microarchitecture. James C. Hoe Department of ECE Carnegie Mellon University
 8 447 Lecture 3: Single Cycle Microarchitecture James C. Hoe Department of ECE Carnegie Mellon University 8 447 S8 L03 S, James C. Hoe, CMU/ECE/CALCM, 208 Your goal today Housekeeping first try at implementing
8 447 Lecture 3: Single Cycle Microarchitecture James C. Hoe Department of ECE Carnegie Mellon University 8 447 S8 L03 S, James C. Hoe, CMU/ECE/CALCM, 208 Your goal today Housekeeping first try at implementing
The single-cycle design from last time
 lticycle path Last time we saw a single-cycle path and control nit for or simple IPS-based instrction set. A mlticycle processor fies some shortcomings in the single-cycle CPU. Faster instrctions are not
lticycle path Last time we saw a single-cycle path and control nit for or simple IPS-based instrction set. A mlticycle processor fies some shortcomings in the single-cycle CPU. Faster instrctions are not
EEC 483 Computer Organization
 EEC 483 Compter Organization Chapter 4.4 A Simple Implementation Scheme Chans Y The Big Pictre The Five Classic Components of a Compter Processor Control emory Inpt path Otpt path & Control 2 path and
EEC 483 Compter Organization Chapter 4.4 A Simple Implementation Scheme Chans Y The Big Pictre The Five Classic Components of a Compter Processor Control emory Inpt path Otpt path & Control 2 path and
The extra single-cycle adders
 lticycle Datapath As an added bons, we can eliminate some of the etra hardware from the single-cycle path. We will restrict orselves to sing each fnctional nit once per cycle, jst like before. Bt since
lticycle Datapath As an added bons, we can eliminate some of the etra hardware from the single-cycle path. We will restrict orselves to sing each fnctional nit once per cycle, jst like before. Bt since
Quiz #1 EEC 483, Spring 2019
 Qiz # EEC 483, Spring 29 Date: Jan 22 Name: Eercise #: Translate the following instrction in C into IPS code. Eercise #2: Translate the following instrction in C into IPS code. Hint: operand C is stored
Qiz # EEC 483, Spring 29 Date: Jan 22 Name: Eercise #: Translate the following instrction in C into IPS code. Eercise #2: Translate the following instrction in C into IPS code. Hint: operand C is stored
Pipelining. Chapter 4
 Pipelining Chapter 4 ake processor rns faster Pipelining is an implementation techniqe in which mltiple instrctions are overlapped in eection Key of making processor fast Pipelining Single cycle path we
Pipelining Chapter 4 ake processor rns faster Pipelining is an implementation techniqe in which mltiple instrctions are overlapped in eection Key of making processor fast Pipelining Single cycle path we
EXAMINATIONS 2010 END OF YEAR NWEN 242 COMPUTER ORGANIZATION
 EXAINATIONS 2010 END OF YEAR COPUTER ORGANIZATION Time Allowed: 3 Hors (180 mintes) Instrctions: Answer all qestions. ake sre yor answers are clear and to the point. Calclators and paper foreign langage
EXAINATIONS 2010 END OF YEAR COPUTER ORGANIZATION Time Allowed: 3 Hors (180 mintes) Instrctions: Answer all qestions. ake sre yor answers are clear and to the point. Calclators and paper foreign langage
EXAMINATIONS 2003 END-YEAR COMP 203. Computer Organisation
 EXAINATIONS 2003 COP203 END-YEAR Compter Organisation Time Allowed: 3 Hors (180 mintes) Instrctions: Answer all qestions. There are 180 possible marks on the eam. Calclators and foreign langage dictionaries
EXAINATIONS 2003 COP203 END-YEAR Compter Organisation Time Allowed: 3 Hors (180 mintes) Instrctions: Answer all qestions. There are 180 possible marks on the eam. Calclators and foreign langage dictionaries
CS 251, Winter 2018, Assignment % of course mark
 CS 25, Winter 28, Assignment 4.. 3% of corse mark De Wednesday, arch 7th, 4:3P Lates accepted ntil Thrsday arch 8th, am with a 5% penalty. (6 points) In the diagram below, the mlticycle compter from the
CS 25, Winter 28, Assignment 4.. 3% of corse mark De Wednesday, arch 7th, 4:3P Lates accepted ntil Thrsday arch 8th, am with a 5% penalty. (6 points) In the diagram below, the mlticycle compter from the
Review Multicycle: What is Happening. Controlling The Multicycle Design
 Review lticycle: What is Happening Reslt Zero Op SrcA SrcB Registers Reg Address emory em Data Sign etend Shift left Sorce A B Ot [-6] [5-] [-6] [5-] [5-] Instrction emory IR RegDst emtoreg IorD em em
Review lticycle: What is Happening Reslt Zero Op SrcA SrcB Registers Reg Address emory em Data Sign etend Shift left Sorce A B Ot [-6] [5-] [-6] [5-] [5-] Instrction emory IR RegDst emtoreg IorD em em
Prof. Kozyrakis. 1. (10 points) Consider the following fragment of Java code:
 Consider the following fragment of Java code:") EE8 Winter 25 Homework #2 Soltions De Thrsday, Feb 2, 5 P. ( points) Consider the following fragment of Java code: for (i=; i
EE8 Winter 25 Homework #2 Soltions De Thrsday, Feb 2, 5 P. ( points) Consider the following fragment of Java code: for (i=; i
Review: Computer Organization
 Review: Compter Organization Pipelining Chans Y Landry Eample Landry Eample Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 3 mintes A B C D Dryer takes 3 mintes
Review: Compter Organization Pipelining Chans Y Landry Eample Landry Eample Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 3 mintes A B C D Dryer takes 3 mintes
Design of Digital Circuits Lecture 13: Multi-Cycle Microarch. Prof. Onur Mutlu ETH Zurich Spring April 2017
 Design of Digital Circuits Lecture 3: Multi-Cycle Microarch. Prof. Onur Mutlu ETH Zurich Spring 27 6 April 27 Agenda for Today & Next Few Lectures! Single-cycle Microarchitectures! Multi-cycle and Microprogrammed
Design of Digital Circuits Lecture 3: Multi-Cycle Microarch. Prof. Onur Mutlu ETH Zurich Spring 27 6 April 27 Agenda for Today & Next Few Lectures! Single-cycle Microarchitectures! Multi-cycle and Microprogrammed
What do we have so far? Multi-Cycle Datapath
 What do we have so far? lti-cycle Datapath CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instrction being processed in datapath How to lower CPI frther? #1 Lec # 8 Spring2 4-11-2 Pipelining pipelining
What do we have so far? lti-cycle Datapath CPI: R-Type = 4, Load = 5, Store 4, Branch = 3 Only one instrction being processed in datapath How to lower CPI frther? #1 Lec # 8 Spring2 4-11-2 Pipelining pipelining
CS 251, Spring 2018, Assignment 3.0 3% of course mark
 CS 25, Spring 28, Assignment 3. 3% of corse mark De onday, Jne 25th, 5:3 P. (5 points) Consider the single-cycle compter shown on page 6 of this assignment. Sppose the circit elements take the following
CS 25, Spring 28, Assignment 3. 3% of corse mark De onday, Jne 25th, 5:3 P. (5 points) Consider the single-cycle compter shown on page 6 of this assignment. Sppose the circit elements take the following
Exceptions and interrupts
 Eceptions and interrpts An eception or interrpt is an nepected event that reqires the CPU to pase or stop the crrent program. Eception handling is the hardware analog of error handling in software. Classes
Eceptions and interrpts An eception or interrpt is an nepected event that reqires the CPU to pase or stop the crrent program. Eception handling is the hardware analog of error handling in software. Classes
CS 251, Winter 2019, Assignment % of course mark
 CS 25, Winter 29, Assignment.. 3% of corse mark De Wednesday, arch 3th, 5:3P Lates accepted ntil Thrsday arch th, pm with a 5% penalty. (7 points) In the diagram below, the mlticycle compter from the corse
CS 25, Winter 29, Assignment.. 3% of corse mark De Wednesday, arch 3th, 5:3P Lates accepted ntil Thrsday arch th, pm with a 5% penalty. (7 points) In the diagram below, the mlticycle compter from the corse
Lecture 9: Microcontrolled Multi-Cycle Implementations. Who Am I?
 18-447 Lecture 9: Microcontrolled Multi-Cycle Implementations S 10 L9-1 James C. Hoe José F. Martínez Electrical & Computer Engineering Carnegie Mellon University February 1, 2010 Who Am I? S 10 L9-2 Associate
18-447 Lecture 9: Microcontrolled Multi-Cycle Implementations S 10 L9-1 James C. Hoe José F. Martínez Electrical & Computer Engineering Carnegie Mellon University February 1, 2010 Who Am I? S 10 L9-2 Associate
CS 251, Winter 2018, Assignment % of course mark
 CS 25, Winter 28, Assignment 3.. 3% of corse mark De onday, Febrary 26th, 4:3 P Lates accepted ntil : A, Febrary 27th with a 5% penalty. IEEE 754 Floating Point ( points): (a) (4 points) Complete the following
CS 25, Winter 28, Assignment 3.. 3% of corse mark De onday, Febrary 26th, 4:3 P Lates accepted ntil : A, Febrary 27th with a 5% penalty. IEEE 754 Floating Point ( points): (a) (4 points) Complete the following
1048: Computer Organization
 8: Compter Organization Lectre 6 Pipelining Lectre6 - pipelining (cwli@twins.ee.nct.ed.tw) 6- Otline An overview of pipelining A pipelined path Pipelined control Data hazards and forwarding Data hazards
8: Compter Organization Lectre 6 Pipelining Lectre6 - pipelining (cwli@twins.ee.nct.ed.tw) 6- Otline An overview of pipelining A pipelined path Pipelined control Data hazards and forwarding Data hazards
Lecture 7. Building A Simple Processor
 Lectre 7 Bilding A Simple Processor Christos Kozyrakis Stanford University http://eeclass.stanford.ed/ee8b C. Kozyrakis EE8b Lectre 7 Annoncements Upcoming deadlines Lab is de today Demo by 5pm, report
Lectre 7 Bilding A Simple Processor Christos Kozyrakis Stanford University http://eeclass.stanford.ed/ee8b C. Kozyrakis EE8b Lectre 7 Annoncements Upcoming deadlines Lab is de today Demo by 5pm, report
The multicycle datapath. Lecture 10 (Wed 10/15/2008) Finite-state machine for the control unit. Implementing the FSM
 Finite-state machine for the control unit. Implementing the FSM") Lectre (Wed /5/28) Lab # Hardware De Fri Oct 7 HW #2 IPS programming, de Wed Oct 22 idterm Fri Oct 2 IorD The mlticycle path SrcA Today s objectives: icroprogramming Etending the mlti-cycle path lti-cycle
Lectre (Wed /5/28) Lab # Hardware De Fri Oct 7 HW #2 IPS programming, de Wed Oct 22 idterm Fri Oct 2 IorD The mlticycle path SrcA Today s objectives: icroprogramming Etending the mlti-cycle path lti-cycle
Enhanced Performance with Pipelining
 Chapter 6 Enhanced Performance with Pipelining Note: The slides being presented represent a mi. Some are created by ark Franklin, Washington University in St. Lois, Dept. of CSE. any are taken from the
Chapter 6 Enhanced Performance with Pipelining Note: The slides being presented represent a mi. Some are created by ark Franklin, Washington University in St. Lois, Dept. of CSE. any are taken from the
CSE Introduction to Computer Architecture Chapter 5 The Processor: Datapath & Control
 CSE-45432 Introdction to Compter Architectre Chapter 5 The Processor: Datapath & Control Dr. Izadi Data Processor Register # PC Address Registers ALU memory Register # Register # Address Data memory Data
CSE-45432 Introdction to Compter Architectre Chapter 5 The Processor: Datapath & Control Dr. Izadi Data Processor Register # PC Address Registers ALU memory Register # Register # Address Data memory Data
Solutions for Chapter 6 Exercises
 Soltions for Chapter 6 Eercises Soltions for Chapter 6 Eercises 6. 6.2 a. Shortening the ALU operation will not affect the speedp obtained from pipelining. It wold not affect the clock cycle. b. If the
Soltions for Chapter 6 Eercises Soltions for Chapter 6 Eercises 6. 6.2 a. Shortening the ALU operation will not affect the speedp obtained from pipelining. It wold not affect the clock cycle. b. If the
1048: Computer Organization
 48: Compter Organization Lectre 5 Datapath and Control Lectre5B - mlticycle implementation (cwli@twins.ee.nct.ed.tw) 5B- Recap: A Single-Cycle Processor PCSrc 4 Add Shift left 2 Add ALU reslt PC address
48: Compter Organization Lectre 5 Datapath and Control Lectre5B - mlticycle implementation (cwli@twins.ee.nct.ed.tw) 5B- Recap: A Single-Cycle Processor PCSrc 4 Add Shift left 2 Add ALU reslt PC address
CSEN 601: Computer System Architecture Summer 2014
 CSEN 601: Computer System Architecture Summer 2014 Practice Assignment 5 Solutions Exercise 5-1: (Midterm Spring 2013) a. What are the values of the control signals (except ALUOp) for each of the following
CSEN 601: Computer System Architecture Summer 2014 Practice Assignment 5 Solutions Exercise 5-1: (Midterm Spring 2013) a. What are the values of the control signals (except ALUOp) for each of the following
Overview of Pipelining
 EEC 58 Compter Architectre Pipelining Department of Electrical Engineering and Compter Science Cleveland State University Fndamental Principles Overview of Pipelining Pipelined Design otivation: Increase
EEC 58 Compter Architectre Pipelining Department of Electrical Engineering and Compter Science Cleveland State University Fndamental Principles Overview of Pipelining Pipelined Design otivation: Increase
TDT4255 Friday the 21st of October. Real world examples of pipelining? How does pipelining influence instruction
 Review Friday the 2st of October Real world eamples of pipelining? How does pipelining pp inflence instrction latency? How does pipelining inflence instrction throghpt? What are the three types of hazard
Review Friday the 2st of October Real world eamples of pipelining? How does pipelining pp inflence instrction latency? How does pipelining inflence instrction throghpt? What are the three types of hazard
PART I: Adding Instructions to the Datapath. (2 nd Edition):
:") EE57 Instrctor: G. Pvvada ===================================================================== Homework #5b De: check on the blackboard =====================================================================
EE57 Instrctor: G. Pvvada ===================================================================== Homework #5b De: check on the blackboard =====================================================================
Chapter 3 & Appendix C Pipelining Part A: Basic and Intermediate Concepts
 CS359: Compter Architectre Chapter 3 & Appendi C Pipelining Part A: Basic and Intermediate Concepts Yanyan Shen Department of Compter Science and Engineering Shanghai Jiao Tong University 1 Otline Introdction
CS359: Compter Architectre Chapter 3 & Appendi C Pipelining Part A: Basic and Intermediate Concepts Yanyan Shen Department of Compter Science and Engineering Shanghai Jiao Tong University 1 Otline Introdction
ELEC 5200/6200 Computer Architecture and Design Spring 2017 Lecture 4: Datapath and Control
 ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
ELEC 52/62 Computer Architecture and Design Spring 217 Lecture 4: Datapath and Control Ujjwal Guin, Assistant Professor Department of Electrical and Computer Engineering Auburn University, Auburn, AL 36849
The Processor. Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut. CSE3666: Introduction to Computer Architecture
 The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
The Processor Z. Jerry Shi Department of Computer Science and Engineering University of Connecticut CSE3666: Introduction to Computer Architecture Introduction CPU performance factors Instruction count
EEC 483 Computer Organization
 EEC 83 Compter Organization Chapter.6 A Pipelined path Chans Y Pipelined Approach 2 - Cycle time, No. stages - Resorce conflict E E A B C D 3 E E 5 E 2 3 5 2 6 7 8 9 c.y9@csohio.ed Resorces sed in 5 Stages
EEC 83 Compter Organization Chapter.6 A Pipelined path Chans Y Pipelined Approach 2 - Cycle time, No. stages - Resorce conflict E E A B C D 3 E E 5 E 2 3 5 2 6 7 8 9 c.y9@csohio.ed Resorces sed in 5 Stages
Lecture 10: Pipelined Implementations
 U 8-7 S 9 L- 8-7 Lectre : Pipelined Implementations James. Hoe ept of EE, U Febrary 23, 29 nnoncements: Project is de this week idterm graded, d reslts posted Handots: H9 Homework 3 (on lackboard) Graded
U 8-7 S 9 L- 8-7 Lectre : Pipelined Implementations James. Hoe ept of EE, U Febrary 23, 29 nnoncements: Project is de this week idterm graded, d reslts posted Handots: H9 Homework 3 (on lackboard) Graded
Chapter 6: Pipelining
 CSE 322 COPUTER ARCHITECTURE II Chapter 6: Pipelining Chapter 6: Pipelining Febrary 10, 2000 1 Clothes Washing CSE 322 COPUTER ARCHITECTURE II The Assembly Line Accmlate dirty clothes in hamper Place in
CSE 322 COPUTER ARCHITECTURE II Chapter 6: Pipelining Chapter 6: Pipelining Febrary 10, 2000 1 Clothes Washing CSE 322 COPUTER ARCHITECTURE II The Assembly Line Accmlate dirty clothes in hamper Place in
PS Midterm 2. Pipelining
 PS idterm 2 Pipelining Seqential Landry 6 P 7 8 9 idnight Time T a s k O r d e r A B C D 3 4 2 3 4 2 3 4 2 3 4 2 Seqential landry takes 6 hors for 4 loads If they learned pipelining, how long wold landry
PS idterm 2 Pipelining Seqential Landry 6 P 7 8 9 idnight Time T a s k O r d e r A B C D 3 4 2 3 4 2 3 4 2 3 4 2 Seqential landry takes 6 hors for 4 loads If they learned pipelining, how long wold landry
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle
Instruction fetch. MemRead. IRWrite ALUSrcB = 01. ALUOp = 00. PCWrite. PCSource = 00. ALUSrcB = 00. R-type completion
 . (Chapter 5) Fill in the vales for SrcA, SrcB, IorD, Dst and emto to complete the Finite State achine for the mlti-cycle datapath shown below. emory address comptation 2 SrcA = SrcB = Op = fetch em SrcA
. (Chapter 5) Fill in the vales for SrcA, SrcB, IorD, Dst and emto to complete the Finite State achine for the mlti-cycle datapath shown below. emory address comptation 2 SrcA = SrcB = Op = fetch em SrcA
Comp 303 Computer Architecture A Pipelined Datapath Control. Lecture 13
 Comp 33 Compter Architectre A Pipelined path Lectre 3 Pipelined path with Signals PCSrc IF/ ID ID/ EX EX / E E / Add PC 4 Address Instrction emory RegWr ra rb rw Registers bsw [5-] [2-6] [5-] bsa bsb Sign
Comp 33 Compter Architectre A Pipelined path Lectre 3 Pipelined path with Signals PCSrc IF/ ID ID/ EX EX / E E / Add PC 4 Address Instrction emory RegWr ra rb rw Registers bsw [5-] [2-6] [5-] bsa bsb Sign
Lecture 8: Data Hazard and Resolution. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
18 447 Lecture 8: Data Hazard and Resolution James C. Hoe Department of ECE Carnegie ellon University 18 447 S18 L08 S1, James C. Hoe, CU/ECE/CALC, 2018 Your goal today Housekeeping detect and resolve
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution
 EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
EC 413 Computer Organization - Fall 2017 Problem Set 3 Problem Set 3 Solution Important guidelines: Always state your assumptions and clearly explain your answers. Please upload your solution document
EECS 151/251A Fall 2017 Digital Design and Integrated Circuits. Instructor: John Wawrzynek and Nicholas Weaver. Lecture 13 EE141
 EECS 151/251A Fall 2017 Digital Design and Integrated Circuits Instructor: John Wawrzynek and Nicholas Weaver Lecture 13 Project Introduction You will design and optimize a RISC-V processor Phase 1: Design
EECS 151/251A Fall 2017 Digital Design and Integrated Circuits Instructor: John Wawrzynek and Nicholas Weaver Lecture 13 Project Introduction You will design and optimize a RISC-V processor Phase 1: Design
Hardware Design Tips. Outline
 Hardware Design Tips EE 36 University of Hawaii EE 36 Fall 23 University of Hawaii Otline Verilog: some sbleties Simlators Test Benching Implementing the IPS Actally a simplified 6 bit version EE 36 Fall
Hardware Design Tips EE 36 University of Hawaii EE 36 Fall 23 University of Hawaii Otline Verilog: some sbleties Simlators Test Benching Implementing the IPS Actally a simplified 6 bit version EE 36 Fall
MIPS Architecture. Fibonacci (C) Fibonacci (Assembly) Another Example: MIPS. Example: subset of MIPS processor architecture
 Fibonacci (Assembly) Another Example: MIPS. Example: subset of MIPS processor architecture") Another Eample: IPS From the Harris/Weste book Based on the IPS-like processor from the Hennessy/Patterson book IPS Architectre Eample: sbset of IPS processor architectre Drawn from Patterson & Hennessy
Another Eample: IPS From the Harris/Weste book Based on the IPS-like processor from the Hennessy/Patterson book IPS Architectre Eample: sbset of IPS processor architectre Drawn from Patterson & Hennessy
Chapter 4. Instruction Execution. Introduction. CPU Overview. Multiplexers. Chapter 4 The Processor 1. The Processor.
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN. 5 th Edition. The Hardware/Software Interface. Chapter 4. The Processor
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition Chapter 4 The Processor COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface 5 th Edition The Processor - Introduction
Chapter 4. The Processor. Computer Architecture and IC Design Lab
 Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
Chapter 4 The Processor Introduction CPU performance factors CPI Clock Cycle Time Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware 4.1 Introduction We will examine two MIPS implementations
Mark Redekopp and Gandhi Puvvada, All rights reserved. EE 357 Unit 15. Single-Cycle CPU Datapath and Control
 EE 37 Unit Single-Cycle CPU path and Control CPU Organization Scope We will build a CPU to implement our subset of the MIPS ISA Memory Reference Instructions: Load Word (LW) Store Word (SW) Arithmetic
EE 37 Unit Single-Cycle CPU path and Control CPU Organization Scope We will build a CPU to implement our subset of the MIPS ISA Memory Reference Instructions: Load Word (LW) Store Word (SW) Arithmetic
EECS150 - Digital Design Lecture 10- CPU Microarchitecture. Processor Microarchitecture Introduction
 EECS150 - Digital Design Lecture 10- CPU Microarchitecture Feb 18, 2010 John Wawrzynek Spring 2010 EECS150 - Lec10-cpu Page 1 Processor Microarchitecture Introduction Microarchitecture: how to implement
EECS150 - Digital Design Lecture 10- CPU Microarchitecture Feb 18, 2010 John Wawrzynek Spring 2010 EECS150 - Lec10-cpu Page 1 Processor Microarchitecture Introduction Microarchitecture: how to implement
Lecture 7 Pipelining. Peng Liu.
 Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Lecture 7 Pipelining Peng Liu liupeng@zju.edu.cn 1 Review: The Single Cycle Processor 2 Review: Given Datapath,RTL -> Control Instruction Inst Memory Adr Op Fun Rt
Computer and Information Sciences College / Computer Science Department The Processor: Datapath and Control
 Computer and Information Sciences College / Computer Science Department The Processor: Datapath and Control Chapter 5 The Processor: Datapath and Control Big Picture: Where are We Now? Performance of a
Computer and Information Sciences College / Computer Science Department The Processor: Datapath and Control Chapter 5 The Processor: Datapath and Control Big Picture: Where are We Now? Performance of a
Chapter 6 Enhancing Performance with. Pipelining. Pipelining. Pipelined vs. Single-Cycle Instruction Execution: the Plan. Pipelining: Keep in Mind
 Pipelining hink of sing machines in landry services Chapter 6 nhancing Performance with Pipelining 6 P 7 8 9 A ime ask A B C ot pipelined Assme 3 min. each task wash, dry, fold, store and that separate
Pipelining hink of sing machines in landry services Chapter 6 nhancing Performance with Pipelining 6 P 7 8 9 A ime ask A B C ot pipelined Assme 3 min. each task wash, dry, fold, store and that separate
COMPUTER ORGANIZATION AND DESIGN. The Hardware/Software Interface. Chapter 4. The Processor: A Based on P&H
 COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
COMPUTER ORGANIZATION AND DESIGN The Hardware/Software Interface Chapter 4 The Processor: A Based on P&H Introduction We will examine two MIPS implementations A simplified version A more realistic pipelined
Processor (I) - datapath & control. Hwansoo Han
 - datapath & control. Hwansoo Han") Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Processor (I) - datapath & control Hwansoo Han Introduction CPU performance factors Instruction count - Determined by ISA and compiler CPI and Cycle time - Determined by CPU hardware We will examine two
Full Datapath. CSCI 402: Computer Architectures. The Processor (2) 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI
 3/21/19. Fengguang Song Department of Computer & Information Science IUPUI") CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
CSCI 42: Computer Architectures The Processor (2) Fengguang Song Department of Computer & Information Science IUPUI Full Datapath Branch Target Instruction Fetch Immediate 4 Today s Contents We have looked
LECTURE 5. Single-Cycle Datapath and Control
 LECTURE 5 Single-Cycle Datapath and Control PROCESSORS In lecture 1, we reminded ourselves that the datapath and control are the two components that come together to be collectively known as the processor.
LECTURE 5 Single-Cycle Datapath and Control PROCESSORS In lecture 1, we reminded ourselves that the datapath and control are the two components that come together to be collectively known as the processor.
CPE 335 Computer Organization. Basic MIPS Architecture Part I
 CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
CPE 335 Computer Organization Basic MIPS Architecture Part I Dr. Iyad Jafar Adapted from Dr. Gheith Abandah slides http://www.abandah.com/gheith/courses/cpe335_s8/index.html CPE232 Basic MIPS Architecture
COMP303 - Computer Architecture Lecture 8. Designing a Single Cycle Datapath
 COMP33 - Computer Architecture Lecture 8 Designing a Single Cycle Datapath The Big Picture The Five Classic Components of a Computer Processor Input Control Memory Datapath Output The Big Picture: The
COMP33 - Computer Architecture Lecture 8 Designing a Single Cycle Datapath The Big Picture The Five Classic Components of a Computer Processor Input Control Memory Datapath Output The Big Picture: The
Lab 8 (All Sections) Prelab: ALU and ALU Control
 Prelab: ALU and ALU Control") Lab 8 (All Sections) Prelab: and Control Name: Sign the following statement: On my honor, as an Aggie, I have neither given nor received nathorized aid on this academic work Objective In this lab yo will
Lab 8 (All Sections) Prelab: and Control Name: Sign the following statement: On my honor, as an Aggie, I have neither given nor received nathorized aid on this academic work Objective In this lab yo will
CS2214 COMPUTER ARCHITECTURE & ORGANIZATION SPRING 2014
 CS COPTER ARCHITECTRE & ORGANIZATION SPRING DE : TA HOEWORK IV READ : i) Related portions of Chapter (except Sections. through.) ii) Related portions of Appendix A iii) Related portions of Appendix iv)
CS COPTER ARCHITECTRE & ORGANIZATION SPRING DE : TA HOEWORK IV READ : i) Related portions of Chapter (except Sections. through.) ii) Related portions of Appendix A iii) Related portions of Appendix iv)
CS 2506 Computer Organization II
 Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet. No calculators or other computing devices may
Instructions: Print your name in the space provided below. This examination is closed book and closed notes, aside from the permitted one-page formula sheet. No calculators or other computing devices may
COMP2611: Computer Organization. The Pipelined Processor
 COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
COMP2611: Computer Organization The 1 2 Background 2 High-Performance Processors 3 Two techniques for designing high-performance processors by exploiting parallelism: Multiprocessing: parallelism among
CSSE232 Computer Architecture I. Mul5cycle Datapath
 CSSE232 Compter Architectre I Ml5cycle Datapath Class Stats Next 3 days : Ml5cycle datapath ing Ml5cycle datapath is not in the book! How long do instrc5ons take? ALU 2ns Mem 2ns Reg File 1ns Everything
CSSE232 Compter Architectre I Ml5cycle Datapath Class Stats Next 3 days : Ml5cycle datapath ing Ml5cycle datapath is not in the book! How long do instrc5ons take? ALU 2ns Mem 2ns Reg File 1ns Everything
Computer Organization and Structure
 Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
Computer Organization and Structure 1. Assuming the following repeating pattern (e.g., in a loop) of branch outcomes: Branch outcomes a. T, T, NT, T b. T, T, T, NT, NT Homework #4 Due: 2014/12/9 a. What
are Softw Instruction Set Architecture Microarchitecture are rdw
 Program, Application Software Programming Language Compiler/Interpreter Operating System Instruction Set Architecture Hardware Microarchitecture Digital Logic Devices (transistors, etc.) Solid-State Physics
Program, Application Software Programming Language Compiler/Interpreter Operating System Instruction Set Architecture Hardware Microarchitecture Digital Logic Devices (transistors, etc.) Solid-State Physics
Lecture 5: The Processor
 Lecture 5: The Processor CSCE 26 Computer Organization Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, text etc included in slides are borrowed from various books, websites, authors pages, and
Lecture 5: The Processor CSCE 26 Computer Organization Instructor: Saraju P. ohanty, Ph. D. NOTE: The figures, text etc included in slides are borrowed from various books, websites, authors pages, and
Lecture 2: RISC V Instruction Set Architecture. Housekeeping
 S 17 L2 1 18 447 Lecture 2: RISC V Instruction Set Architecture James C. Hoe Department of ECE Carnegie Mellon University Housekeeping S 17 L2 2 Your goal today get bootstrapped on RISC V RV32I to start
S 17 L2 1 18 447 Lecture 2: RISC V Instruction Set Architecture James C. Hoe Department of ECE Carnegie Mellon University Housekeeping S 17 L2 2 Your goal today get bootstrapped on RISC V RV32I to start
361 datapath.1. Computer Architecture EECS 361 Lecture 8: Designing a Single Cycle Datapath
 361 datapath.1 Computer Architecture EECS 361 Lecture 8: Designing a Single Cycle Datapath Outline of Today s Lecture Introduction Where are we with respect to the BIG picture? Questions and Administrative
361 datapath.1 Computer Architecture EECS 361 Lecture 8: Designing a Single Cycle Datapath Outline of Today s Lecture Introduction Where are we with respect to the BIG picture? Questions and Administrative
CS3350B Computer Architecture Quiz 3 March 15, 2018
 CS3350B Computer Architecture Quiz 3 March 15, 2018 Student ID number: Student Last Name: Question 1.1 1.2 1.3 2.1 2.2 2.3 Total Marks The quiz consists of two exercises. The expected duration is 30 minutes.
CS3350B Computer Architecture Quiz 3 March 15, 2018 Student ID number: Student Last Name: Question 1.1 1.2 1.3 2.1 2.2 2.3 Total Marks The quiz consists of two exercises. The expected duration is 30 minutes.
Inf2C - Computer Systems Lecture Processor Design Single Cycle
 Inf2C - Computer Systems Lecture 10-11 Processor Design Single Cycle Boris Grot School of Informatics University of Edinburgh Previous lectures Combinational circuits Combinations of gates (INV, AND, OR,
Inf2C - Computer Systems Lecture 10-11 Processor Design Single Cycle Boris Grot School of Informatics University of Edinburgh Previous lectures Combinational circuits Combinations of gates (INV, AND, OR,
Lecture 2: RISC V Instruction Set Architecture. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 2: RISC V Instruction Set Architecture James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L02 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping get bootstrapped
18 447 Lecture 2: RISC V Instruction Set Architecture James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L02 S1, James C. Hoe, CMU/ECE/CALCM, 2018 Your goal today Housekeeping get bootstrapped
Improving Performance: Pipelining
 Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
Improving Performance: Pipelining Memory General registers Memory ID EXE MEM WB Instruction Fetch (includes PC increment) ID Instruction Decode + fetching values from general purpose registers EXE EXEcute
The overall datapath for RT, lw,sw beq instrucution
 Designing The Main Control Unit: Remember the three instruction classes {R-type, Memory, Branch}: a) R-type : Op rs rt rd shamt funct 1.src 2.src dest. 31-26 25-21 20-16 15-11 10-6 5-0 a) Memory : Op rs
Designing The Main Control Unit: Remember the three instruction classes {R-type, Memory, Branch}: a) R-type : Op rs rt rd shamt funct 1.src 2.src dest. 31-26 25-21 20-16 15-11 10-6 5-0 a) Memory : Op rs
CO Computer Architecture and Programming Languages CAPL. Lecture 18 & 19
 CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
CO2-3224 Computer Architecture and Programming Languages CAPL Lecture 8 & 9 Dr. Kinga Lipskoch Fall 27 Single Cycle Disadvantages & Advantages Uses the clock cycle inefficiently the clock cycle must be
PIPELINING. Pipelining: Natural Phenomenon. Pipelining. Pipelining Lessons
 Pipelining: Natral Phenomenon Landry Eample: nn, rian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 mintes C D Dryer takes 0 mintes PIPELINING Folder takes 20 mintes
Pipelining: Natral Phenomenon Landry Eample: nn, rian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 mintes C D Dryer takes 0 mintes PIPELINING Folder takes 20 mintes
EEC 483 Computer Organization. Branch (Control) Hazards
 Hazards") EEC 483 Compter Organization Section 4.8 Branch Hazards Section 4.9 Exceptions Chans Y Branch (Control) Hazards While execting a previos branch, next instrction address might not yet be known. s n i o
EEC 483 Compter Organization Section 4.8 Branch Hazards Section 4.9 Exceptions Chans Y Branch (Control) Hazards While execting a previos branch, next instrction address might not yet be known. s n i o
Lecture 13: Exceptions and Interrupts
 18 447 Lectre 13: Eceptions and Interrpts S 10 L13 1 James C. Hoe Dept of ECE, CU arch 1, 2010 Annoncements: Handots: Spring break is almost here Check grades on Blackboard idterm 1 graded Handot #9: Lab
18 447 Lectre 13: Eceptions and Interrpts S 10 L13 1 James C. Hoe Dept of ECE, CU arch 1, 2010 Annoncements: Handots: Spring break is almost here Check grades on Blackboard idterm 1 graded Handot #9: Lab
EECS150 - Digital Design Lecture 9- CPU Microarchitecture. Watson: Jeopardy-playing Computer
 EECS150 - Digital Design Lecture 9- CPU Microarchitecture Feb 15, 2011 John Wawrzynek Spring 2011 EECS150 - Lec09-cpu Page 1 Watson: Jeopardy-playing Computer Watson is made up of a cluster of ninety IBM
EECS150 - Digital Design Lecture 9- CPU Microarchitecture Feb 15, 2011 John Wawrzynek Spring 2011 EECS150 - Lec09-cpu Page 1 Watson: Jeopardy-playing Computer Watson is made up of a cluster of ninety IBM
ECE232: Hardware Organization and Design
 ECE232: Hardware Organization and Design Lecture 14: One Cycle MIPs Datapath Adapted from Computer Organization and Design, Patterson & Hennessy, UCB R-Format Instructions Read two register operands Perform
ECE232: Hardware Organization and Design Lecture 14: One Cycle MIPs Datapath Adapted from Computer Organization and Design, Patterson & Hennessy, UCB R-Format Instructions Read two register operands Perform
Lecture Topics. Announcements. Today: Single-Cycle Processors (P&H ) Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)
 Next: continued. Milestone #3 (due 2/9) Milestone #4 (due 2/23)") Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
Lecture Topics Today: Single-Cycle Processors (P&H 4.1-4.4) Next: continued 1 Announcements Milestone #3 (due 2/9) Milestone #4 (due 2/23) Exam #1 (Wednesday, 2/15) 2 1 Exam #1 Wednesday, 2/15 (3:00-4:20
ECE232: Hardware Organization and Design
 ECE232: Harware Organization an Design ectre 11: Introction to IPs path apte from Compter Organization an Design, Patterson & Hennessy, CB IPS-lite processor Compter Want to bil a processor for a sbset
ECE232: Harware Organization an Design ectre 11: Introction to IPs path apte from Compter Organization an Design, Patterson & Hennessy, CB IPS-lite processor Compter Want to bil a processor for a sbset
ECE473 Computer Architecture and Organization. Processor: Combined Datapath
 Computer Architecture and Organization Processor: Combined path Lecturer: Prof. Yifeng Zhu Fall, 2014 Portions of these slides are derived from: Dave Patterson CB 1 Where are we? Want to build a processor
Computer Architecture and Organization Processor: Combined path Lecturer: Prof. Yifeng Zhu Fall, 2014 Portions of these slides are derived from: Dave Patterson CB 1 Where are we? Want to build a processor
Single-Cycle Examples, Multi-Cycle Introduction
 Single-Cycle Examples, ulti-cycle Introduction 1 Today s enu Single cycle examples Single cycle machines vs. multi-cycle machines Why multi-cycle? Comparative performance Physical and Logical Design of
Single-Cycle Examples, ulti-cycle Introduction 1 Today s enu Single cycle examples Single cycle machines vs. multi-cycle machines Why multi-cycle? Comparative performance Physical and Logical Design of
CS 152 Computer Architecture and Engineering Lecture 4 Pipelining
 CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
CS 152 Computer rchitecture and Engineering Lecture 4 Pipelining 2014-1-30 John Lazzaro (not a prof - John is always OK) T: Eric Love www-inst.eecs.berkeley.edu/~cs152/ Play: 1 otorola 68000 Next week
ECE 486/586. Computer Architecture. Lecture # 7
 ECE 486/586 Computer Architecture Lecture # 7 Spring 2015 Portland State University Lecture Topics Instruction Set Principles Instruction Encoding Role of Compilers The MIPS Architecture Reference: Appendix
ECE 486/586 Computer Architecture Lecture # 7 Spring 2015 Portland State University Lecture Topics Instruction Set Principles Instruction Encoding Role of Compilers The MIPS Architecture Reference: Appendix
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1
 Chapter 4.1") Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Lecture 3: The Processor (Chapter 4 of textbook) Chapter 4.1 Introduction Chapter 4.1 Chapter 4.2 Review: MIPS (RISC) Design Principles Simplicity favors regularity fixed size instructions small number
Processor. Han Wang CS3410, Spring 2012 Computer Science Cornell University. See P&H Chapter , 4.1 4
 Processor Han Wang CS3410, Spring 2012 Computer Science Cornell University See P&H Chapter 2.16 20, 4.1 4 Announcements Project 1 Available Design Document due in one week. Final Design due in three weeks.
Processor Han Wang CS3410, Spring 2012 Computer Science Cornell University See P&H Chapter 2.16 20, 4.1 4 Announcements Project 1 Available Design Document due in one week. Final Design due in three weeks.
Chapter 4. The Processor
 Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified
Chapter 4 The Processor Introduction CPU performance factors Instruction count Determined by ISA and compiler CPI and Cycle time Determined by CPU hardware We will examine two MIPS implementations A simplified